KubeBlocks Tutorial 501 – Auto-Tuning for Optimal Performance

Welcome to the fifth chapter of our KubeBlocks tutorial series!
In this tutorial, we dive into Operator Capability Level 5, focusing on Auto-Tuning. You’ll learn how KubeBlocks dynamically adjusts database parameters based on resource specifications to optimize performance, reducing manual intervention.
👋 If you find KubeBlocks helpful, please consider giving us a star ⭐️ on our GitHub repository. Your support drives us to improve!
Prerequisites
To save you time, we’ve automatically installed KubeBlocks and created a MySQL cluster in the background. The setup might take a few minutes—feel free to proceed, but some commands may require the installation to complete first.
If you’re new to KubeBlocks or missed earlier tutorials, check out:
- KubeBlocks Tutorial 101 – Getting Started
- KubeBlocks Tutorial 201 - Seamless Upgrades
- KubeBlocks Tutorial 301 - Backup & Restore
- KubeBlocks Tutorial 401 – Observability in Action
1. Introduction
What is Auto-Tuning?
At Operator Capability Level 5, Auto-Tuning refers to the Operator’s ability to dynamically adjust an application’s configuration based on workload patterns or resource changes, ensuring optimal performance with minimal manual effort. KubeBlocks supports this by automatically tuning database parameters (e.g., MySQL’s max_connections) when resource specifications (like memory) are updated.
Why does even MySQL bother to limit max_connections?
MySQL limits connections for resource management reasons. Each connection consumes memory resources, including various buffers allocated for that connection.
MySQL needs to reserve substantial memory for its buffer pool to cache data and indexes for efficient query performance.
If connections were unlimited, too many connections could consume excessive memory, squeezing the space available for the buffer pool, ultimately leading to degraded query performance.
Therefore, limiting max_connections is a necessary measure to protect database performance and stability.
Goals of This Tutorial
In this lab, we’ll:
- Demonstrate how KubeBlocks auto-tunes MySQL parameters based on resource changes.
- Optimize configurations to showcase the "Auto Pilot" philosophy of reducing manual intervention.
Key Features:
- Parameter Auto-Tuning: Adjusts database settings based on resource specs.
- Automation Focus: Minimizes manual configuration for better efficiency.
- Performance Insights: Leverages Prometheus and Grafana for bottleneck detection.
2. Auto-Tuning in Action: Dynamic Parameter Adjustment
Let’s explore how KubeBlocks auto-tunes MySQL parameters when resources change.
2.1 Check Initial Parameters
Connect to the MySQL cluster:
kbcli cluster connect mycluster -n demo
Then inspect the max_connections parameter:
mysql> SHOW VARIABLES LIKE 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 83 |
+-----------------+-------+
1 row in set (0.01 sec)
2.2 Adjust Resources and Trigger Auto-Tuning
Increase the memory from 0.5Gi to 1Gi:
kbcli cluster vscale mycluster -n demo --components=mysql --cpu=500m --memory=1000Mi
Wait a few seconds for the MySQL pod to restart, Then recheck max_connections:
kbcli cluster connect mycluster -n demo
Then inspect the max_connections parameter:
mysql> SHOW VARIABLES LIKE 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 163 |
+-----------------+-------+
1 row in set (0.01 sec)
KubeBlocks detected the memory increase and automatically adjusted max_connections to optimize for the new resource capacity.
Why is max_connections limited to 163 with 1000Mi memory?
KubeBlocks calculates max_connections in MySQL as (PhysicalMemory - innodb_buffer_pool_size) / single_thread_memory as a best practice for resource optimization.
This approach ensures efficient memory use by reserving most memory (typically 75%) for the innodb_buffer_pool_size to cache data, reducing disk I/O, while allocating the rest to client connections.
It prevents memory exhaustion by limiting connections based on per-thread memory needs (e.g., thread_stack, join_buffer_size), avoiding crashes under high load.
This balance enhances performance and stability, making it ideal for containerized environments like Kubernetes where resources are constrained and predictable scaling is key.
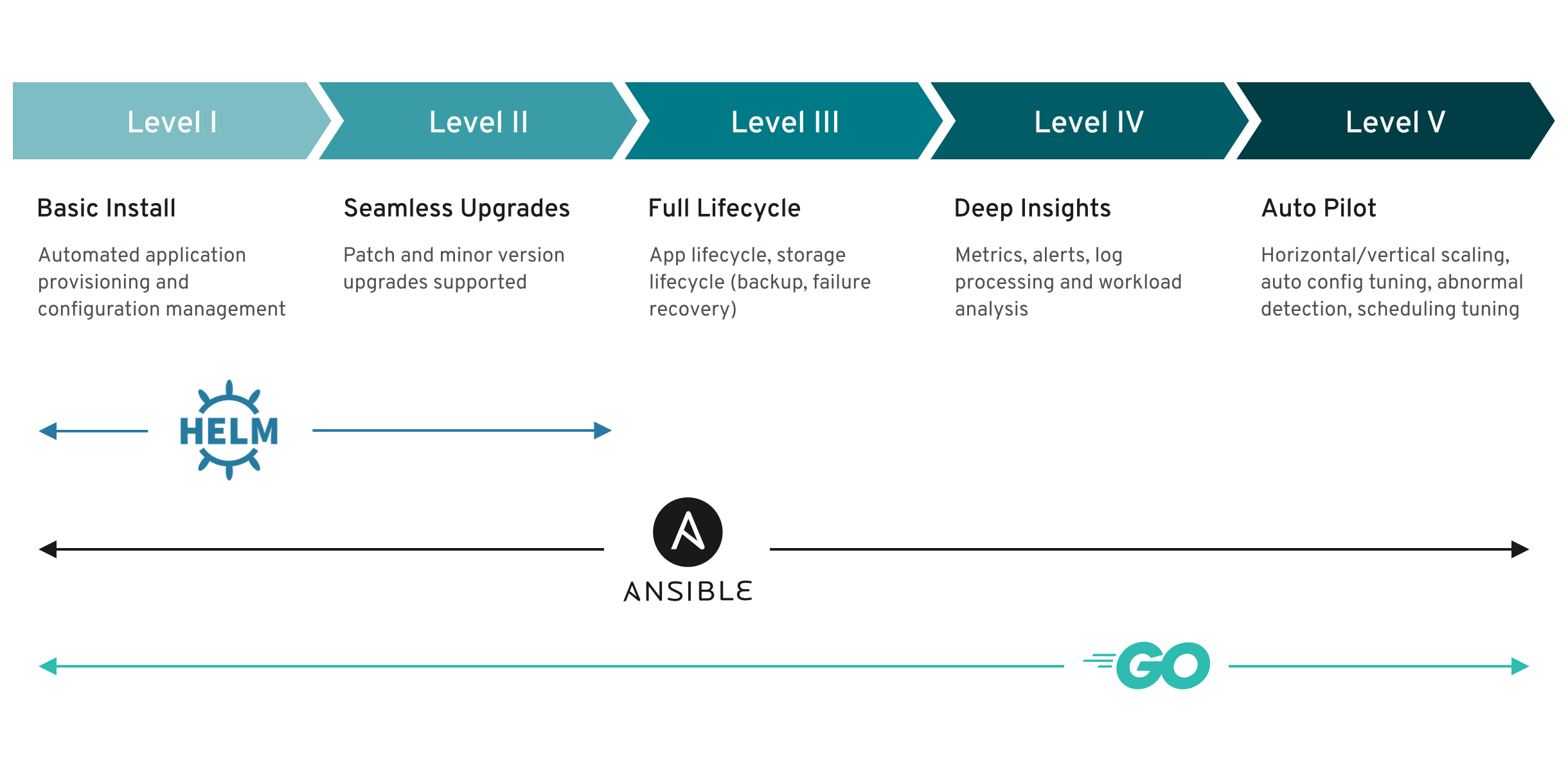
3. KubeBlocks and Operator Capability Level 5
Operator Capability Level 5 represents the highest level of Operator maturity, aiming to achieve an “Auto Pilot” state that minimizes manual intervention to the greatest extent possible. The core features of Level 5 include Auto-Scaling, Auto-Healing, Abnormality Detection, and Auto-Tuning. Let’s examine how KubeBlocks performs at this level.
3.1 Support for Manual Scaling
KubeBlocks provides robust support for manual scaling, including:
- Scale In/Out (Horizontal Scaling): Users can increase or decrease the number of database instances.
- Scale Up/Down (Vertical Scaling): Users can adjust the resource configurations of individual instances, such as CPU and memory.
For example, using the kbcli cluster vscale command (as demonstrated in Section 2.2), users can easily modify the memory allocation for a MySQL instance. This manual scaling capability offers flexibility, allowing users to adapt the cluster size to workload demands. However, KubeBlocks does not currently support automatic scaling, meaning it cannot dynamically adjust the number of instances or resources based on load metrics (e.g., requests per second).
3.2 Automatic Parameter Tuning
When it comes to auto-tuning, KubeBlocks excels. It automatically adjusts database parameters in response to changes in resource specifications. For instance, after increasing the memory allocated to MySQL, KubeBlocks updates the max_connections parameter to match the new resource capacity. This feature reduces the need for manual parameter adjustments, ensuring that database performance remains aligned with available resources.
3.3 Auto-Healing and Abnormality Detection
KubeBlocks demonstrates strong capabilities in auto-healing and abnormality detection:
- Automatic Restarts and Failover: Upon detecting a Pod failure, KubeBlocks not only restarts the Pod but can also perform a switch-over, promptly reassigning the leader role to a healthy instance. This mechanism significantly enhances database high availability, enabling rapid service recovery, especially during primary node failures.
- Monitoring Integration: Through integration with Prometheus and Grafana, KubeBlocks continuously monitors database health and performance metrics in real-time, detecting anomalies and triggering corrective actions as needed.
4. Summary
In this tutorial, we explored KubeBlocks’ Auto-Tuning capabilities:
- Automatically adjusting parameters like
max_connectionsbased on resource specs. - Reducing manual intervention for efficient database management.
While KubeBlocks doesn’t yet support auto-scaling, its parameter tuning aligns with Level 5’s “Auto Pilot” vision. Stay tuned for future enhancements like automated scaling!
5. What’s Next?
- Experiment with Auto-Tuning on other engines.
- Customize configuration templates for specific workloads.
- Keep an eye on KubeBlocks updates for more Level 5 features.
- Visit kubeblocks.io to explore additional features and capabilities KubeBlocks has to offer!
About the Author
Writes about
Frequently covers