How Container Images Actually Work: Layers, Configs, Manifests, Indexes, and More
Premium Tutorial
Upgrade your membership to unlock this and all other premium materials.
This write-up is my attempt to explain the container image format as it's described by the OCI Image Specification and, to a lesser extent, the OCI Distribution Specification. The post will focus on such well-known (but not so well understood) concepts as image layers, image configuration, image manifests, and image indexes. We'll also talk about image IDs and image digests, and how images are stored and addressed locally and in registries. Traditionally, the idea is to show why each of these moving parts is needed, when it's used, and how the parts work together instead of just describing them in dry terms, rehashing the spec(s).
By the end of it, you should be able to explain how the same docker pull nginx:alpine command ends up fetching different images on an amd64 Linux server and an arm64 macOS laptop, why the exact same image may get different digests when moved from one registry to another (but its ID will never change), and what exactly constitutes a single- and multi-platform container image.
The knowledge will come in handy if you often deal with:
- Building multi-platform images
- Moving images between registries
- Performing provenance attestations
- Comparing images (by digests or IDs)
- Running images across container runtimes (e.g., Lima in development, Docker in CI/CD, and Kubernetes in production)
Sounds relevant? Buckle up for a deep dive!
Disclaimer: This write-up is by no means as complete as the OCI Image Specification - the spec is (likely intentionally) more abstract, and because of that more generic, while this post tries to be rather concrete and focuses on the most typical day-to-day applications of container images. The post may not be utterly accurate either, but I'm doing my best to not deviate from the spec too much or interpret it too freely.
What Is a Container Image?
At its core, a container image is an archive with the application, all its direct and transitive dependencies, required OS packages, and a container execution configuration inside.
In other words, an image binds together two key "things":
- Filesystem (
rootfs) - one or more tar archives, which often (but not always) produce a typical Linux root filesystem layout when unpacked. - Configuration - a piece of JSON, which describes the image itself and also defines the default parameters for containers started from it (e.g., the command to run, the environment variables to set, etc.).
The purpose of a container image is to hold all necessary information for an OCI runtime (e.g., runc) to prepare and start a container.
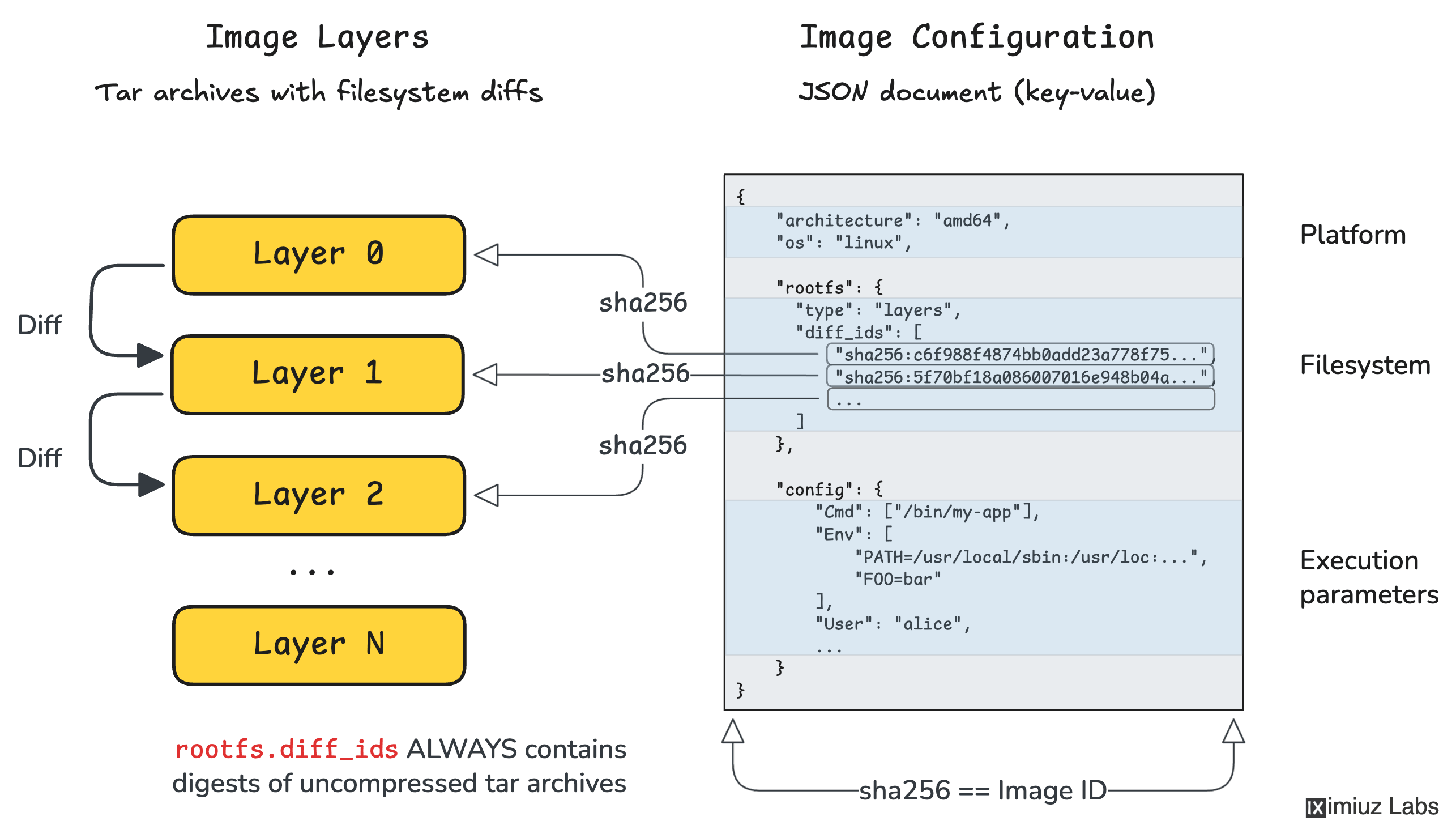
OCI Image Configuration
The image configuration JSON format is standardized by the OCI spec. And it's actually a pretty simple and straightforward one!
Here is a minimal example of an image configuration that shows ALL required fields (there are just 3) and one optional but usually present field called config (yep, it's configuration's config, you got it right):
{
"architecture": "amd64", // required field
"os": "linux", // required field
"rootfs": { // required field
"type": "layers", // required value
"diff_ids": [
"sha256:c6f988f4874bb0add23a778f753...b66bbd1",
"sha256:5f70bf18a086007016e948b04ae...ce3c6ef",
...
]
},
"config": { // optional but usually present
"Cmd": ["/bin/my-app"],
"Env": [
"PATH=/usr/local/sbin:/usr/local/bin:...",
"FOO=bar"
],
"User": "alice"
}
}
There are two important observations about the image configuration format we should make as they will be important for connecting the dots later on:
- OCI Image Configuration is an inherently single-platform construct - i.e., given an image configuration, you should always be able to tell its target platform (e.g.,
linux/amd64). - In addition to the application's runtime parameters (
.config), the configuration also references the application's filesystem (.rootfs).
Thus, OCI Image Configuration is not just a bag of environment variables and an entrypoint. It also says "this runtime configuration goes with exactly this container filesystem template."
Premium Materials
Official Content Pack required
This platform is funded entirely by the community. Please consider supporting iximiuz Labs by upgrading your membership to unlock access to this and all other learning materials in the Official Collection.
Support Development