Network Traffic Rate Limiting with eBPF/XDP

In the previous tutorial, we learned how to capture and parse network packets using eBPF/XDP. That was a good starting point, but building any useful programs also requires other eBPF features like eBPF maps and helper functions.
The complexity of different applications naturally depends on the problem, but one of the simplest—and also one of the first—examples I built early on was packet rate limiting.
Packet rate limiting is quite common today because of the large number of scrapers collecting data for AI training and the growing number of attacks that try to overwhelm servers or take down websites.
But it’s not only about limiting potentially bad traffic. Rate limiting also helps ensure fair API usage or enforce usage tiers (for example, 10 requests per second).
This tutorial won’t come close to a production-ready tool — a real system would also use techniques like TCP/TLS fingerprinting. Still, it’s a great way to understand how eBPF/XDP can enforce rate-limiting rules directly in the kernel.
Nonetheless, the approaches to rate limiting mainly differ in how they decide whether a client should be limited, while the actual enforcement logic is mostly the same.
In this tutorial, we’ll focus on building a solution that rate-limits network traffic based on the client’s IP address.
High-Level Concept
In general, most network packet rate-limiting solutions follow the same three steps:
- Capture incoming client traffic
- Check/Store the request against a table of rate-limit rules
- Enforce the rule (allow, delay, or drop)
When we map this idea to eBPF, the flow looks very similar:
- Capture and parse packet metadata using eBPF/XDP — in our case, we extract the client IP from the IPv6 header.
- Check/Store per-client state — we keep the client’s IPv6 address and the timestamp of their last allowed packet in an eBPF map.
- Enforce rate limits — by comparing the current timestamp with the stored one and deciding whether to allow or drop the packet.
But while it might sound trivial to simply rate-limit all packets, things can get a bit trickier.
For example, imagine you want to rate-limit HTTP requests. Since HTTP typically runs over TCP, it also involves the TCP handshake—and you usually don’t want to slow down that handshake. Throttling it would make new connections feel broken before the actual HTTP traffic even begins.
However, once a client has already exceeded the limit, even their handshake packets should be dropped. Otherwise, they could keep opening new connections that would immediately be rate-limited anyway.
To keep things simple in this tutorial, we’ll avoid these nuances and focus on rate-limiting ICMPv6 traffic instead. There’s no handshake involved—each packet is just a single echo request (ping).
First, we need to extract the client’s IPv6 address from the captured network packet, just like we did in the first tutorial:
SEC("xdp")
int xdp_program(struct xdp_md *ctx) {
void *data_end = (void *)(unsigned long long)ctx->data_end;
void *data = (void *)(unsigned long long)ctx->data;
struct hdr_cursor nh;
nh.pos = data;
// For simplicity we only showcase IPv6 ICMP rate-limiting
struct ethhdr *eth;
int eth_type = parse_ethhdr(&nh, data_end, ð);
if (eth_type == bpf_htons(ETH_P_IPV6)) {
struct ipv6hdr *ipv6;
int ip_type = parse_ip6hdr(&nh, data_end, &ipv6);
...
if (ip_type == IPPROTO_ICMPV6) {
// Parse ICMP header
struct icmp6hdr *icmp6;
int icmp6_type = parse_icmp6hdr(&nh, data_end, &icmp6);
...
if (icmp6->icmp6_type == ICMPV6_ECHO_REQUEST) {
bpf_printk("We have captured an ICMPv6 packet");
bpf_printk("IPv6 src: %x:%x:%x:%x:%x:%x:%x:%x",
bpf_ntohs(ipv6->saddr.in6_u.u6_addr16[0]),
bpf_ntohs(ipv6->saddr.in6_u.u6_addr16[1]),
bpf_ntohs(ipv6->saddr.in6_u.u6_addr16[2]),
bpf_ntohs(ipv6->saddr.in6_u.u6_addr16[3]),
bpf_ntohs(ipv6->saddr.in6_u.u6_addr16[4]),
bpf_ntohs(ipv6->saddr.in6_u.u6_addr16[5]),
bpf_ntohs(ipv6->saddr.in6_u.u6_addr16[6]),
bpf_ntohs(ipv6->saddr.in6_u.u6_addr16[7]));
bpf_printk("Echo id=%d seq=%d",
bpf_ntohs(icmp6->icmp6_dataun.u_echo.identifier),
bpf_ntohs(icmp6->icmp6_dataun.u_echo.sequence));
More information about ICMPv6 network traffic
💡 For ICMP network traffic, we need to distinguish between echo request and echo reply packets. We can do this using the icmp6->icmp6_type field:
int icmp6_type = parse_icmp6hdr(&nh, data_end, &icmp6);
...
if (icmp6->icmp6_type == ICMPV6_ECHO_REQUEST) {
// handle echo request
}
For simplicity, I’ve hard-coded the ICMPV6_ECHO_REQUEST and ICMPV6_ECHO_REPLY values (from linux/icmpv6.h) inside parse_helpers.h file:
#define ICMPV6_ECHO_REQUEST 128
#define ICMPV6_ECHO_REPLY 129
Someone who remembers from the first tutorial that an eBPF/XDP program only runs on the ingress path might wonder - Why do we even need to check for ICMPV6_ECHO_REQUEST? Isn’t the host only receiving requests anyways?
It’s true that in our case the server is only gonna be receiving echo requests from a client. But imagine if you'd ping the client from the server, the server’s XDP program would receive the echo reply (ICMPV6_ECHO_REPLY). Without checking the type, the program could mistakenly handle replies using the logic meant for echo requests.
That’s why we’re a bit more explicit in the program and check the packet type.
If you’ve followed along with the last tutorial, this logic shouldn’t surprise you in any way.
Now, to implement rate limiting like allowing 1 ICMPv6 packet per 2 seconds, we need to store each client’s IPv6 address along with the timestamp of their last packet. For this, we’ll use:
- an eBPF map of type
BPF_MAP_TYPE_LRU_HASH, which stores, in our case, the client’s IPv6 address as the key and the last packet timestamp as the value.
struct {
__uint(type, BPF_MAP_TYPE_LRU_HASH);
__uint(max_entries, 65536);
__type(key, struct ipv6_key); // IPv6 address
__type(value, __u64); // last allowed ts (ns)
} last_time SEC(".maps");
💡 This eBPF map is similar to BPF_MAP_TYPE_HASH, except the LRU behavior automatically removes old entries when the map is full, ensuring we don’t get stuck with no room for new clients.
- the
bpf_ktime_get_ns()helper function, which returns the time elapsed since system boot in nanoseconds and later allows us to calculate how much time has passed since the last packet from a given client.
...
if (icmp6->icmp6_type == ICMPV6_ECHO_REQUEST) {
...
struct ipv6_key key = {};
__builtin_memcpy(&key.addr, &ipv6->saddr, sizeof(key.addr)); // copy 16 bytes of IPv6 into key
__u64 now = bpf_ktime_get_ns(); // Get current time from boot in ns
__u64 *lastp = bpf_map_lookup_elem(&last_time, &key); // Check last packet timestamp from this
if (lastp) {
if (now - *lastp < TWO_SECONDS_NS) {
return XDP_DROP; // rate-limit this client by dropping it's packet
}
*lastp = now; // update allowed timestamp
} else {
bpf_map_update_elem(&last_time, &key, &now, BPF_ANY); // First time we see this client: allow it and set timestamp
}
}
...
💡 Notice also how we use XDP_DROP to discard the packet.
In the lab/xdp.c eBPF program, you’ll also see an XDP_PASS action at the end, which simply hands the packet off to the kernel’s network stack as usual.
And that’s really all there is to it. Let's see it in action.
Let's Run It
Current playground has two nodes, server and client respectively.
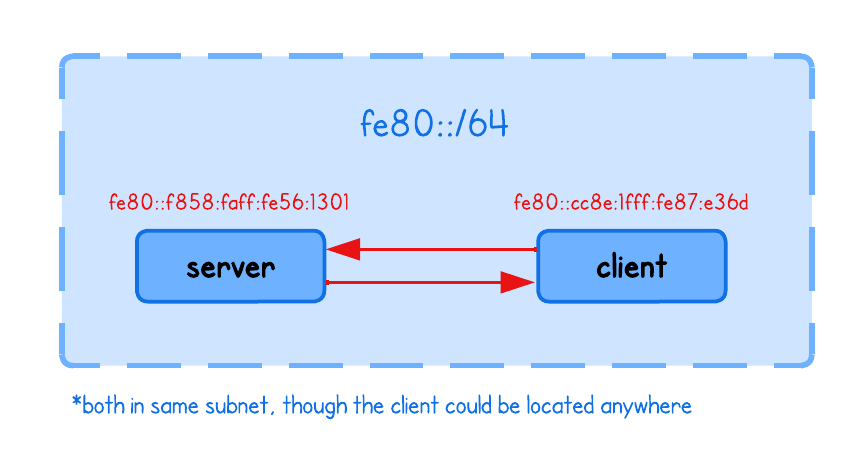
I can’t really hardcode an IPv6 address in the playground (for now), but you can easily find yours using:
ip address show eth0
4: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 02:ab:7b:0f:6e:d5 brd ff:ff:ff:ff:ff:ff
inet 172.16.0.10/24 brd 172.16.0.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::f858:faff:fe56:1301/64 scope link # <- HERE!
valid_lft forever preferred_lft forever
Then compile and run the eBPF program in the lab directory, from the server tab:
go generate
go build
sudo ./xdp -i eth0
What is the `-i eth0` flag?
💡 The input argument (-i eth0) specifies the network interface where the eBPF/XDP program will be attached.
iface, err := net.InterfaceByName(ifname)
if err != nil {
log.Fatalf("Getting interface %s: %s", ifname, err)
}
xdplink, err := link.AttachXDP(link.XDPOptions{
Program: objs.XdpProgram,
Interface: iface.Index,
Flags: link.XDPGenericMode,
})
Finally, ping the server from the client (client tab) using it's IPv6 address:
sudo ping -6 <SERVER-IPv6>
Since the rate limiter allows ICMPv6 packets from a specific client only once every 2 seconds, you should see roughly every other ping (default rate: 1 ping/s) succeed (and every second dropped):
64 bytes from fe80::c07d:5cff:fe2f:3096%eth0: icmp_seq=1 ttl=64 time=0.821 ms
64 bytes from fe80::c07d:5cff:fe2f:3096%eth0: icmp_seq=3 ttl=64 time=0.628 ms
64 bytes from fe80::c07d:5cff:fe2f:3096%eth0: icmp_seq=5 ttl=64 time=0.627 ms
64 bytes from fe80::c07d:5cff:fe2f:3096%eth0: icmp_seq=7 ttl=64 time=0.562 ms
64 bytes from fe80::c07d:5cff:fe2f:3096%eth0: icmp_seq=9 ttl=64 time=0.534 ms
64 bytes from fe80::c07d:5cff:fe2f:3096%eth0: icmp_seq=11 ttl=64 time=0.623 ms
This was a rather short one, where we learned how eBPF maps and XDP_DROP action can be utilized to rate-limit network traffic, but I really like examples like this because they require no interaction with user space — everything is detected and enforced directly in the kernel.
In the next tutorial, we’ll take it a step further and implement an eBPF/XDP firewall. Additionally, instead of blocking individual clients by IP, we’ll handle entire IP ranges using the BPF_MAP_TYPE_LPM_TRIE map type.
About the Author
Writes about
Frequently covers