Hands-On with XDP: eBPF for High-Performance Networking

If you look at the Linux kernel’s networking stack code, it’s built to support a wide range of protocols and features — from IPv4/IPv6 and TCP/UDP to VLANs, tunnels such as VXLAN and GRE, as well as QoS and traffic shaping.
However, every processing step a packet goes through adds microseconds of latency. It may sound small, but at millions of packets per second, this overhead quickly becomes a performance bottleneck that even modern hardware struggles to overcome.
With this in mind, different kernel bypass techniques exist, such as DPDK or PF_RING ZC. These frameworks let user-space applications receive packets directly from the network hardware instead of going through the kernel.
But since these frameworks bypass the kernel, applications must often reimplement many of its networking features—which adds complexity as well as weakens the security mechanism normally provided by the kernel.
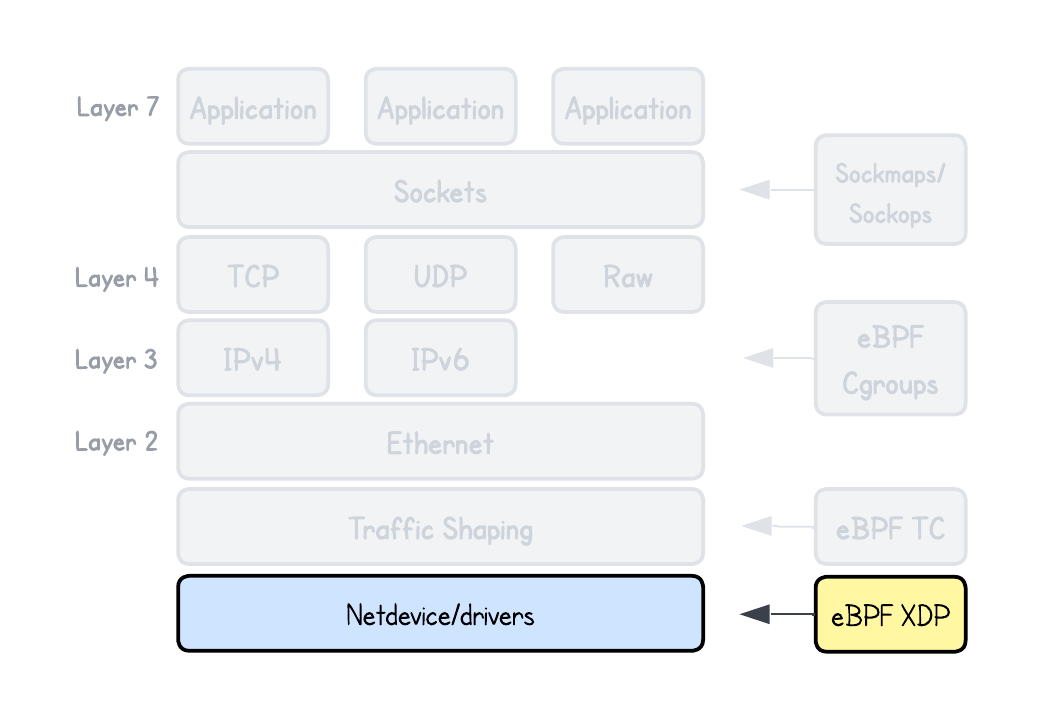
To address these shortcomings, XDP (eXpress Data Path) was introduced. It enables in-kernel packet processing that reuses existing kernel networking and security features instead of reimplementing them in user space.
That’s a rather rough comparison as DPDK can often be more performant, and XDP less complex to implement as it reuses many kernel features—but these are two technologies suited differently across environments, each with its own strengths and trade-offs.
To avoid making any enemies, in this skill path we’ll solely focus on:
- How XDP actually works?
- What kinds of applications is it best suited for?
- When should you consider using other eBPF program types higher up the stack?
This tutorial marks the first step, where you’ll get hands-on experience parsing IPv4/IPv6, TCP/UDP, and ICMP traffic. In later tutorials, these fundamentals will be expanded with more advanced use cases such as packet rate-limiting, firewalling and load balancing.
eBPF/XDP Program Type
XDP (eXpress Data Path) is a type of eBPF program that attaches to the XDP hook point in the Linux kernel’s networking stack. As of now, there are three types of XDP hook points available (or I should say modes):
- Generic mode – runs in the kernel network stack after the
sk_buffallocation and is available on kernel versions v4.8+ - Native (driver) mode – runs directly in the network driver before the
sk_buffallocation, offering higher performance. - Hardware offload mode – runs directly on the Network Interface Card (NIC) itself, achieving the highest performance but limited to supported hardware.
💡 Most common NICs, such as Intel i40e/ice/ixgbe and Mellanox mlx5, support XDP in native or driver mode, while hardware offload remains limited to Netronome SmartNICs.
See the documentation for the full list of supported drivers.
The current playground you’re using only supports Generic mode, but it’s easy to imagine how Native or HW Offload modes could deliver better performance. For example, in an eBPF-based firewall, the earlier you capture a packet, the sooner you can drop it—reducing the overall system load and increasing throughput.

💡 While we can't really compare the different modes of operations in this playground, one of the most costly operations in the kernel’s networking receive path is copying the packet data from the receive buffer (rx_ring) to a data structure called socket buffer (sk_buff).
This is why you would see significant performance gains e.g. in load balancing or dropping high-volume of traffic when toggling between Native/Driver and Generic mode.
And it’s also why, if your program can be developed with XDP, it’s generally preferred over TC, since TC programs run after the socket buffer has already been allocated.
In the case of the ebpf-go framework we’re using, the mode can easily be toggled by specifying the desired option when attaching the XDP program:
xdplink, err := link.AttachXDP(link.XDPOptions{
Program: objs.XdpProgram,
Interface: iface.Index,
Flags: link.XDPGenericMode,
})
Where you can set either XDPGenericMode, XDPDriverMode, or XDPOffloadMode, as defined in the ebpf-go documentation.
💡 Important to mention is that we are also attaching this XDP program to a specific network interface.
iface, err := net.InterfaceByName(ifname)
if err != nil {
log.Fatalf("Getting interface %s: %s", ifname, err)
}
xdplink, err := link.AttachXDP(link.XDPOptions{
Program: objs.XdpProgram,
Interface: iface.Index,
Flags: link.XDPGenericMode,
})
Different network interfaces can have different XDP programs attached.
It’s even possible to load multiple XDP programs on a single network interface, but we’ll cover that in a later tutorial. If you want to get ahead, check out libxdp.
Regardless of mode you set, most XDP programs follow the same pattern:
- Parse the packet — parse L2/L3/L4 headers and extract the fields your application care about.
- Work with metadata — process extracted fields (and lookup or update eBPF maps).
- Modify the packet (less common) — rewrite headers or payload; adjust headroom/tailroom (e.g.,
bpf_xdp_adjust_head/tail) for e.g. IPIP encapsulation or decapsulation. - Return a verdict — exit with an action code that tells the kernel what to do next with the packet.
In light of the last point, XDP supports several actions — or return codes, to be more precise — that define how your program behaves:
- XDP_PASS – allow the packet to continue through the networking stack (as usual)
- XDP_DROP – drop/discard the packet immediately
- XDP_TX – transmit the packet back out the same interface
- XDP_REDIRECT – send the packet to another network interface, CPU or special user-space socket (AF_XDP)
- XDP_ABORTED – used for aborting the program execution due to an error
We'll learn how these actions/return codes are utilized in different use cases in this skill path - but they are here for reference.
How XDP Parses Ethernet, IP, IPv6, TCP, UDP and ICMP Headers
Enough theory — the goal of this tutorial is to understand how we can access the network packet metadata — the ground truth for any application you’ll see out there in the wild.
To start off, let’s first look at what kind of kernel context structure is passed to our eBPF/XDP program:
struct xdp_md {
__u32 data;
__u32 data_end;
__u32 data_meta;
__u32 ingress_ifindex;
__u32 rx_queue_index;
__u32 egress_ifindex;
};
Where fields represents:
- data - Pointer to the start of the packet data (the beginning of the readable memory region)
- data_end - Pointer to the end of the packet data (the end of the readable memory region)
- data_meta - Optional space before data for custom metadata passed from XDP to later stages like TC - see bpf_xdp_adjust_meta for more info.
- ingress_ifindex - Index of the network interface packet was received on
- rx_queue_index - Index of the receive queue on that interface where the packet was queued
- egress_ifindex - Set to the network interface index the packet was redirected out of, but only when the redirect happened
Most of the time, programs only use the data and data_end pointers — not only to access packet data but also to satisfy the eBPF verifier and ensure that all memory access stays within the packet’s boundaries.
In my opinion, making the verifier happy is also one of the hardest parts of XDP development.
To keep things simple, we’ll use the parse_helpers.h header file (originally from the xdp-project/xdp-tutorial repository), which simplifies much of the parsing logic for us.
In short, this header file provides a set of helper functions that safely access packet data and extract Ethernet, IPv4/IPv6, and TCP/UDP headers.
...
#include "parse_helpers.h"
SEC("xdp")
int xdp_program(struct xdp_md *ctx) {
void *data_end = (void *)(unsigned long long)ctx->data_end;
void *data = (void *)(unsigned long long)ctx->data;
struct hdr_cursor nh;
nh.pos = data;
int ip_type;
struct ethhdr *eth;
// Parse Ethernet header
int eth_type = parse_ethhdr(&nh, data_end, ð);
if (eth_type == bpf_htons(ETH_P_IP)) {
// We have captured an IPv4 packet
struct iphdr *ip;
// Parse IPv4 header
ip_type = parse_iphdr(&nh, data_end, &ip);
...
if (ip_type == IPPROTO_ICMP) {
// We have captured an ICMP packet
struct icmphdr *icmp;
// Parse ICMP header
int icmp_type = parse_icmphdr(&nh, data_end, &icmp);
...
}
} else if (eth_type == bpf_htons(ETH_P_IPV6)) {
// We have captured an IPv6 packet
struct ipv6hdr *ipv6;
// Parse IPv6 header
ip_type = parse_ip6hdr(&nh, data_end, &ipv6);
...
if (ip_type == IPPROTO_ICMPV6) {
// We have captured an ICMPv6 packet
struct icmp6hdr *icmp6;
// Parse ICMPv6 header
int icmp6_type = parse_icmp6hdr(&nh, data_end, &icmp6);
...
}
}
if (ip_type == IPPROTO_TCP) {
// We have captured a TCP packet
struct tcphdr *tcp;
// Parse TCP header
int tcp_type = parse_tcphdr(&nh, data_end, &tcp);
...
} else if (ip_type == IPPROTO_UDP) {
// We have captured a UDP packet
struct udphdr *udp;
// Parse UDP header
int udp_type = parse_udphdr(&nh, data_end, &udp);
...
}
...
All of these helpers functions take in:
struct hdr_cursor *nh— a moving “cursor” that is initialy pointing to the beginning of that packet data (nh.pos = data;). Each helper then advancesnh->pospast the header it successfully parses, so subsequent parsing helpers start at the right place.void *data_end— the end of the valid packet region to perform bounds checks so you never read past the packet.<header> **out— an output pointer that points to the parsed header (e.g.,struct ethhdr,struct iphdr, etc.).
If we look at each stage in a bit more details, by parsing the Ethernet header we can distinguish between IPv4 and IPv6 protocol and extract header information accordingly.
SEC("xdp")
int xdp_program(struct xdp_md *ctx) {
void *data_end = (void *)(unsigned long long)ctx->data_end;
void *data = (void *)(unsigned long long)ctx->data;
struct hdr_cursor nh;
nh.pos = data;
int ip_type;
// Parse Ethernet header
struct ethhdr *eth;
int eth_type = parse_ethhdr(&nh, data_end, ð);
if (eth_type == bpf_htons(ETH_P_IP)) {
bpf_printk("We have captured an IPv4 packet");
struct iphdr *ip;
// Parse IPv4 header
ip_type = parse_iphdr(&nh, data_end, &ip);
...
__u32 src = bpf_ntohl(ip->saddr);
__u32 dst = bpf_ntohl(ip->daddr);
bpf_printk("IPv4 src: %d.%d.%d.%d",
(src >> 24) & 0xFF,
(src >> 16) & 0xFF,
(src >> 8) & 0xFF,
src & 0xFF);
bpf_printk("IPv4 dst: %d.%d.%d.%d",
(dst >> 24) & 0xFF,
(dst >> 16) & 0xFF,
(dst >> 8) & 0xFF,
dst & 0xFF);
...
} else if (eth_type == bpf_htons(ETH_P_IPV6)) {
bpf_printk("We have captured an IPv6 packet");
struct ipv6hdr *ipv6;
// Parse IPv6 header
ip_type = parse_ip6hdr(&nh, data_end, &ipv6);
...
// Print as 4x32-bit chunks (hex)
bpf_printk("IPv6 src: %x:%x:%x:%x:%x:%x:%x:%x",
bpf_ntohs(ipv6->saddr.in6_u.u6_addr16[0]),
bpf_ntohs(ipv6->saddr.in6_u.u6_addr16[1]),
bpf_ntohs(ipv6->saddr.in6_u.u6_addr16[2]),
bpf_ntohs(ipv6->saddr.in6_u.u6_addr16[3]),
bpf_ntohs(ipv6->saddr.in6_u.u6_addr16[4]),
bpf_ntohs(ipv6->saddr.in6_u.u6_addr16[5]),
bpf_ntohs(ipv6->saddr.in6_u.u6_addr16[6]),
bpf_ntohs(ipv6->saddr.in6_u.u6_addr16[7]));
bpf_printk("IPv6 dst: %x:%x:%x:%x:%x:%x:%x:%x",
bpf_ntohs(ipv6->daddr.in6_u.u6_addr16[0]),
bpf_ntohs(ipv6->daddr.in6_u.u6_addr16[1]),
bpf_ntohs(ipv6->daddr.in6_u.u6_addr16[2]),
bpf_ntohs(ipv6->daddr.in6_u.u6_addr16[3]),
bpf_ntohs(ipv6->daddr.in6_u.u6_addr16[4]),
bpf_ntohs(ipv6->daddr.in6_u.u6_addr16[5]),
bpf_ntohs(ipv6->daddr.in6_u.u6_addr16[6]),
bpf_ntohs(ipv6->daddr.in6_u.u6_addr16[7]));
...
}
💡 If you look closely at the code, you’ll notice that we’re using eBPF helpers like bpf_ntohs() to convert values from network byte order to host byte order and make them easier to interpret in the program.
For more information about these eBPF helpers and their usage, refer to the official eBPF documentation.
At a minimum, this gives us access to the source and destination IPv4/IPv6 addresses, which can be used to identify clients (by IP), useful for rate limiting or firewall applications.
💡 The IP header also exposes other useful fields — such as TTL, protocol type (TCP/UDP), fragment offset, and total length — that can be leveraged for deeper packet analysis.
Check out struct iphdr or struct ipv6hdr in the lab/vmlinux.h file to see all the packet header fields available to us.
There's that, but our XDP program also showcases how to parse TCP, UDP and ICMP protocols:
SEC("xdp")
int xdp_program(struct xdp_md *ctx) {
void *data_end = (void *)(unsigned long long)ctx->data_end;
void *data = (void *)(unsigned long long)ctx->data;
struct hdr_cursor nh;
nh.pos = data;
int ip_type;
// Parse Ethernet header
struct ethhdr *eth;
int eth_type = parse_ethhdr(&nh, data_end, ð);
if (eth_type == bpf_htons(ETH_P_IP)) {
bpf_printk("We have captured an IPv4 packet");
struct iphdr *ip;
// Parse IPv4 header
ip_type = parse_iphdr(&nh, data_end, &ip);
...
if (ip_type == IPPROTO_ICMP) {
bpf_printk("We have captured an ICMP packet");
// Parse ICMP header
struct icmphdr *icmp;
int icmp_type = parse_icmphdr(&nh, data_end, &icmp);
...
bpf_printk("Type: %d", icmp->type);
bpf_printk("Code: %d", icmp->code);
if (icmp->type == ICMP_ECHO || icmp->type == ICMP_ECHOREPLY) {
bpf_printk("Echo id=%d seq=%d\n",
bpf_ntohs(icmp->un.echo.id),
bpf_ntohs(icmp->un.echo.sequence));
}
}
} else if (eth_type == bpf_htons(ETH_P_IPV6)) {
bpf_printk("We have captured an IPv6 packet");
struct ipv6hdr *ipv6;
// Parse IPv6 header
ip_type = parse_ip6hdr(&nh, data_end, &ipv6);
...
if (ip_type == IPPROTO_ICMPV6) {
bpf_printk("We have captured an ICMP packet");
struct icmp6hdr *icmp6;
// Parse ICMP header
int icmp6_type = parse_icmp6hdr(&nh, data_end, &icmp6);
...
bpf_printk("Type: %d", icmp6->icmp6_type);
bpf_printk("Code: %d", icmp6->icmp6_code);
if (icmp6->icmp6_type == ICMPV6_ECHO_REQUEST || icmp6->icmp6_type == ICMPV6_ECHO_REPLY) {
bpf_printk("Echo id=%d seq=%d\n",
bpf_ntohs(icmp6->icmp6_dataun.u_echo.identifier),
bpf_ntohs(icmp6->icmp6_dataun.u_echo.sequence));
}
}
}
if (ip_type == IPPROTO_TCP) {
bpf_printk("We have captured a TCP packet");
struct tcphdr *tcp;
// Parse TCP header
int tcp_type = parse_tcphdr(&nh, data_end, &tcp);
...
bpf_printk("Source port: %d", bpf_ntohs(tcp->source));
bpf_printk("Destination port: %d", bpf_ntohs(tcp->dest));
bpf_printk("Sequence number: %d", bpf_ntohs(tcp->seq));
bpf_printk("Acknowledgment number: %d", bpf_ntohs(tcp->ack_seq));
bpf_printk("Flags: SYN=%d ACK=%d FIN=%d RST=%d PSH=%d URG=%d ECE=%d CWR=%d",
tcp->syn, tcp->ack, tcp->fin, tcp->rst, tcp->psh, tcp->urg, tcp->ece, tcp->cwr);
} else if (ip_type == IPPROTO_UDP) {
bpf_printk("We have captured a UDP packet");
// Parse UDP header
struct udphdr *udp;
int udp_type = parse_udphdr(&nh, data_end, &udp);
...
bpf_printk("Source port: %d", bpf_ntohs(udp->source));
bpf_printk("Destination port: %d", bpf_ntohs(udp->dest));
bpf_printk("Length of the UDP datagram: %d", bpf_ntohs(udp->len));
bpf_printk("Checksum for error detection: %d", bpf_ntohs(udp->check));
}
...
This way, we can access different fields depending on the type of network packet we’ve captured:
- TCP
- Extracts source and destination ports, sequence and acknowledgment numbers, and flags such as SYN, ACK, FIN, RST, PSH, URG, ECE, and CWR.
- Useful for tracking client connections, detecting SYN floods, and analyzing general TCP traffic (e.g., RTT, retransmissions).
- UDP
- Extracts source and destination ports, datagram length, and checksum.
- Useful for monitoring UDP-based protocols such as DNS or QUIC.
- ICMP / ICMPv6
- Extracts type, code, and—for echo messages—the identifier and sequence fields.
- Useful for monitoring network health, detecting ping sweeps or DoS attempts, and diagnosing connectivity issues.
It should now be much easier to understand how different protocols can be parsed, and how the program can branch into separate code paths—each capable of triggering specific XDP actions and enabling one to develop different types of applications.
Let’s see this in action by observing a simple HTTP request from a client to a server.
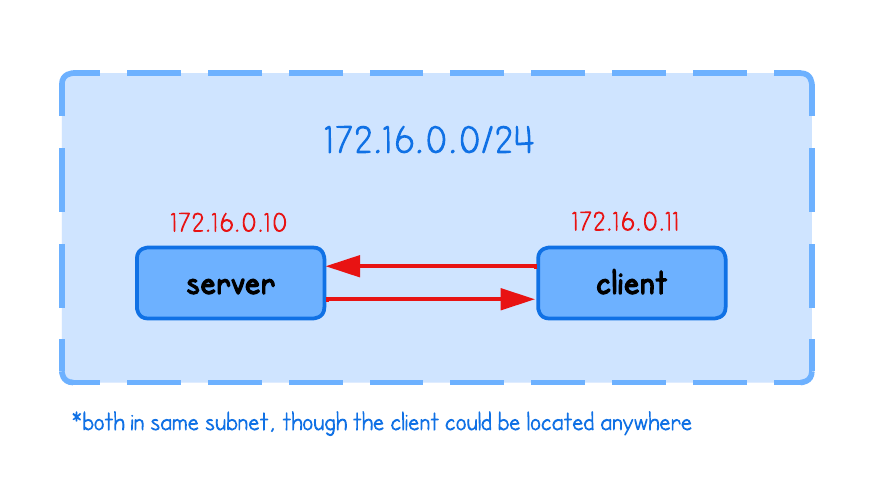
First, start an HTTP server in the server tab:
python3 -m http.server 8000
Next, open another server tab (click + → select server), then build and run our XDP program inside the lab folder:
go generate
go build
sudo ./xdp -i eth0
For simplicity, the program prints packet header information directly to the eBPF trace logs. While we could forward this data to user space, we avoid that complexity for now. Open another server tab and run:
sudo bpftool prog trace
Finally, from the client tab, send a request to the server:
curl http://172.16.0.10:8000/
You should now see your XDP program printing parsed Ethernet, IP and TCP-related packet details in real time.
You’ll notice that the logs contain a lot of network traffic—not just clients' curl request. As a small challenge, try modifying the code so that only packets with TCP destination port 8000 (the HTTP server’s listening port) are printed.
Or, if you prefer a quicker workaround, simply use grep:
sudo bpftool prog trace | grep 8000 -A 4 -B 4
But so far, we’ve only looked at the headers — what about application data like HTTP in our case?
XDP can only access the raw packet data that fits within a single MTU-sized frame, so it can’t always reliably parse application-layer protocols like HTTP. For that, eBPF hooks higher up the stack that operate on reassembled packet streams are more suitable.
We’ll cover those soon, but this limitation is a key reason why developers often combine XDP with other program types—even though XDP is the most performant option and seems ideal for many networking tasks.
Instead of only describing use cases, the upcoming tutorials will walk through building real eBPF applications like packet rate limiting, firewalling and load balancing with XDP.
About the Author
Writes about
Frequently covers