Building an eBPF/XDP IP-in-IP Direct Server Return Load Balancer from Scratch

In the previous tutorial, we built a DSR L2 eBPF/XDP-based load balancer. A key takeaway was how the virtual IP can be shared between the load balancer and backend nodes, as well as keeping the IP header intact, allowing the backend to see the client’s IP.
While this worked nicely, L2 DSR relies on the fact that backend nodes need to be on the same L2 network as the load balancer.
This is quite a constraint, and not quite suitable for cloud environments, where nodes are often distributed across different virtual networks.
To overcome these limitations, DSR IP-in-IP load balancing was introduced.
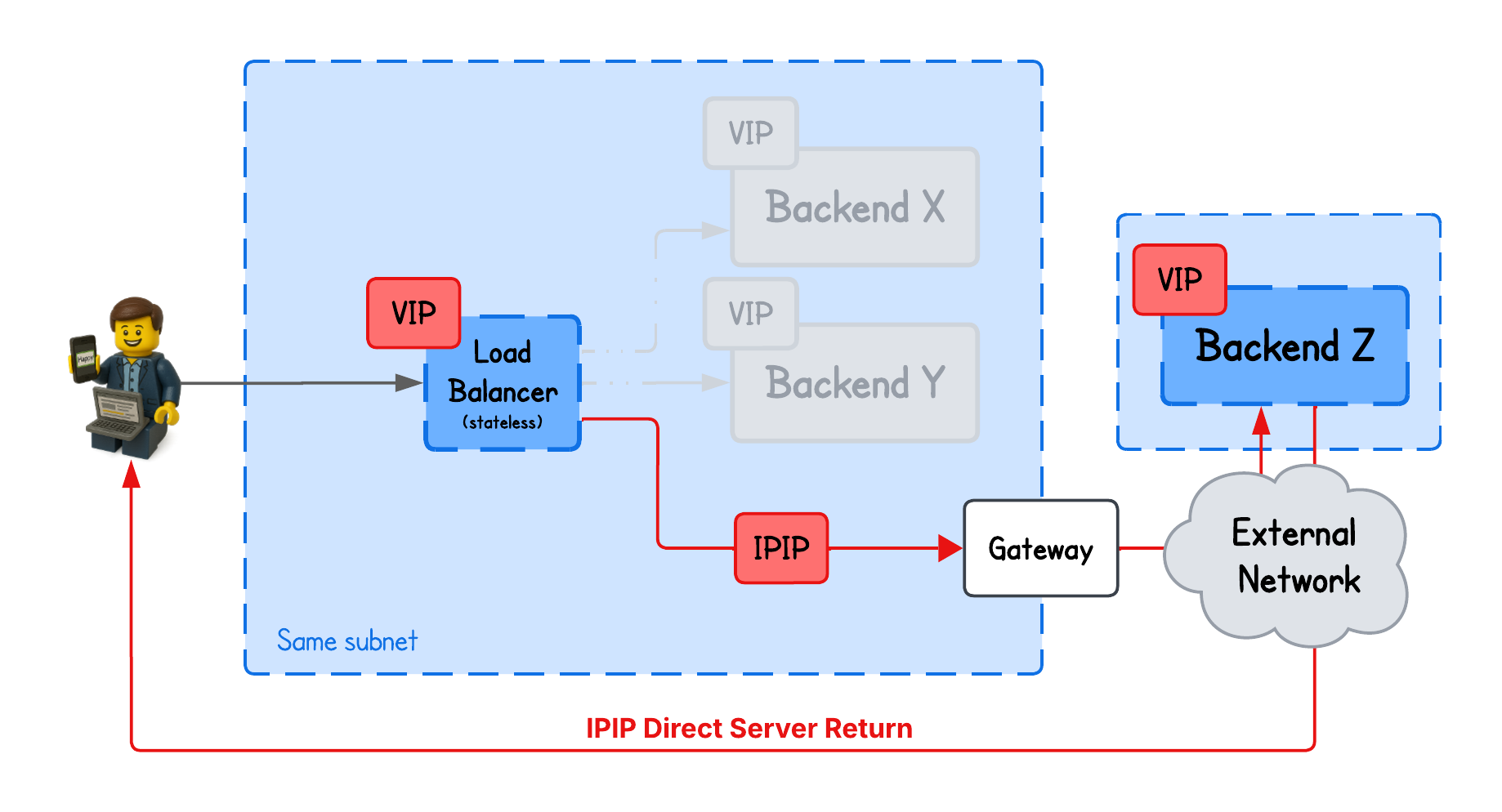
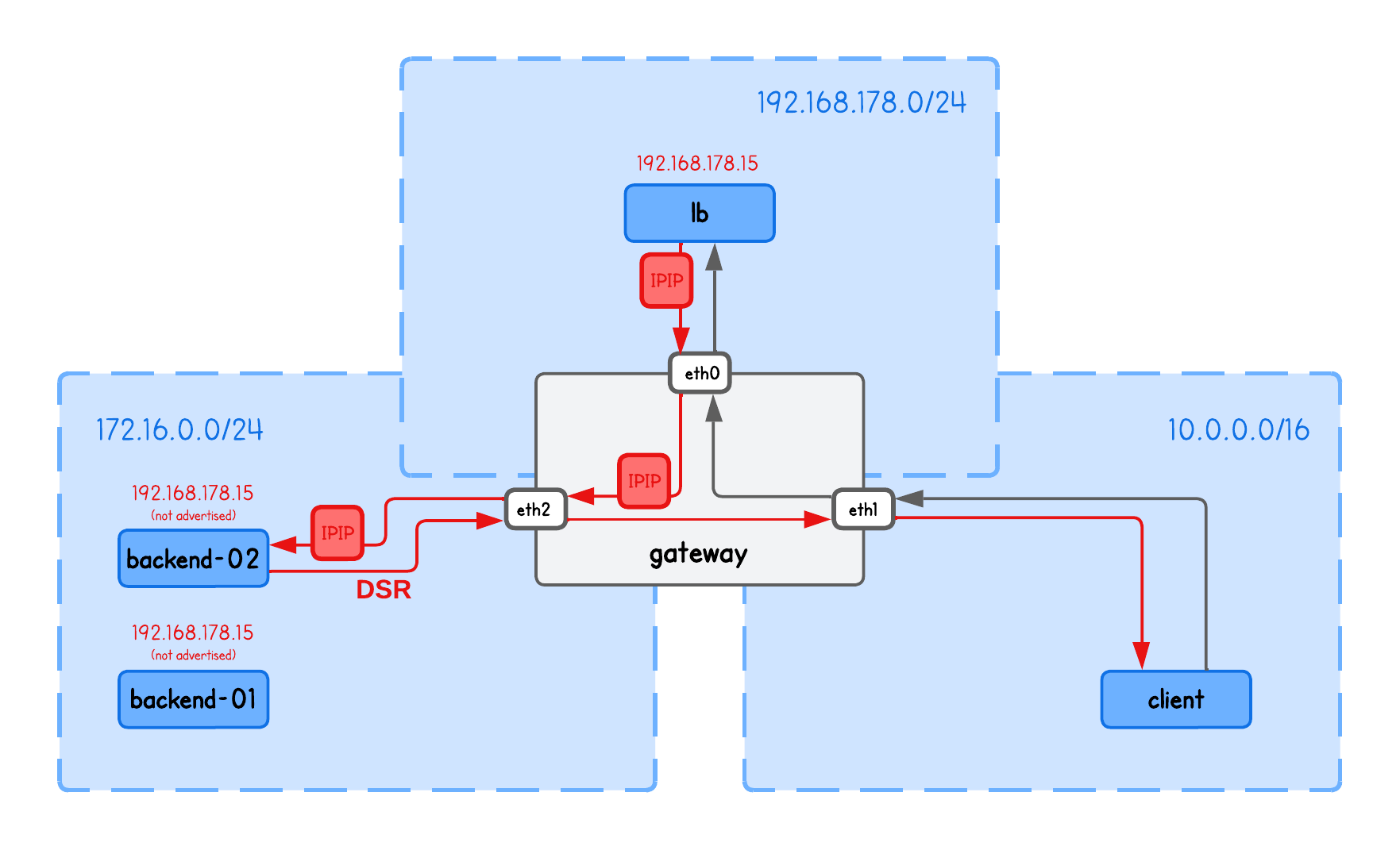
In an IP-in-IP DSR load-balancing setup, backends not only respond directly to clients but can also reside in different networks than the load balancer.
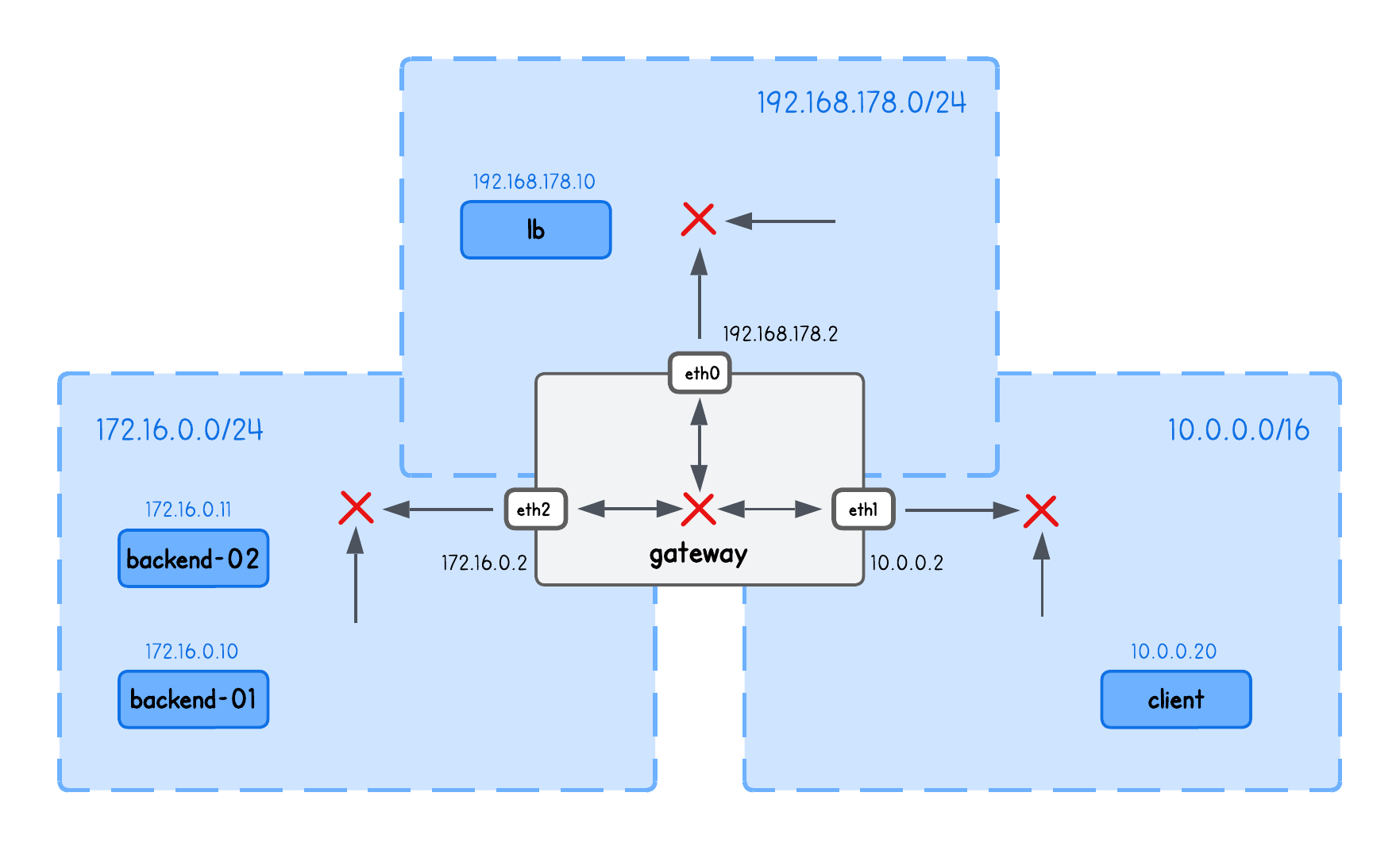
This playground has a network topology with five nodes on three different networks:
lbin network192.168.178.10/24backend-01in network172.16.0.10/24backend-02in network172.16.0.11/24clientin network10.0.0.20/16gatewaybetween networks192.168.178.2/24,10.0.0.2/16,172.16.0.2/24
DSR IPIP Load Balancing
In the L2 DSR load balancing approach, we were only rewriting MAC addresses, which limited the load balancer to operate within the same L2 network. Now, we want to make these packets routable across different networks (load balancer → network-hops → backend).
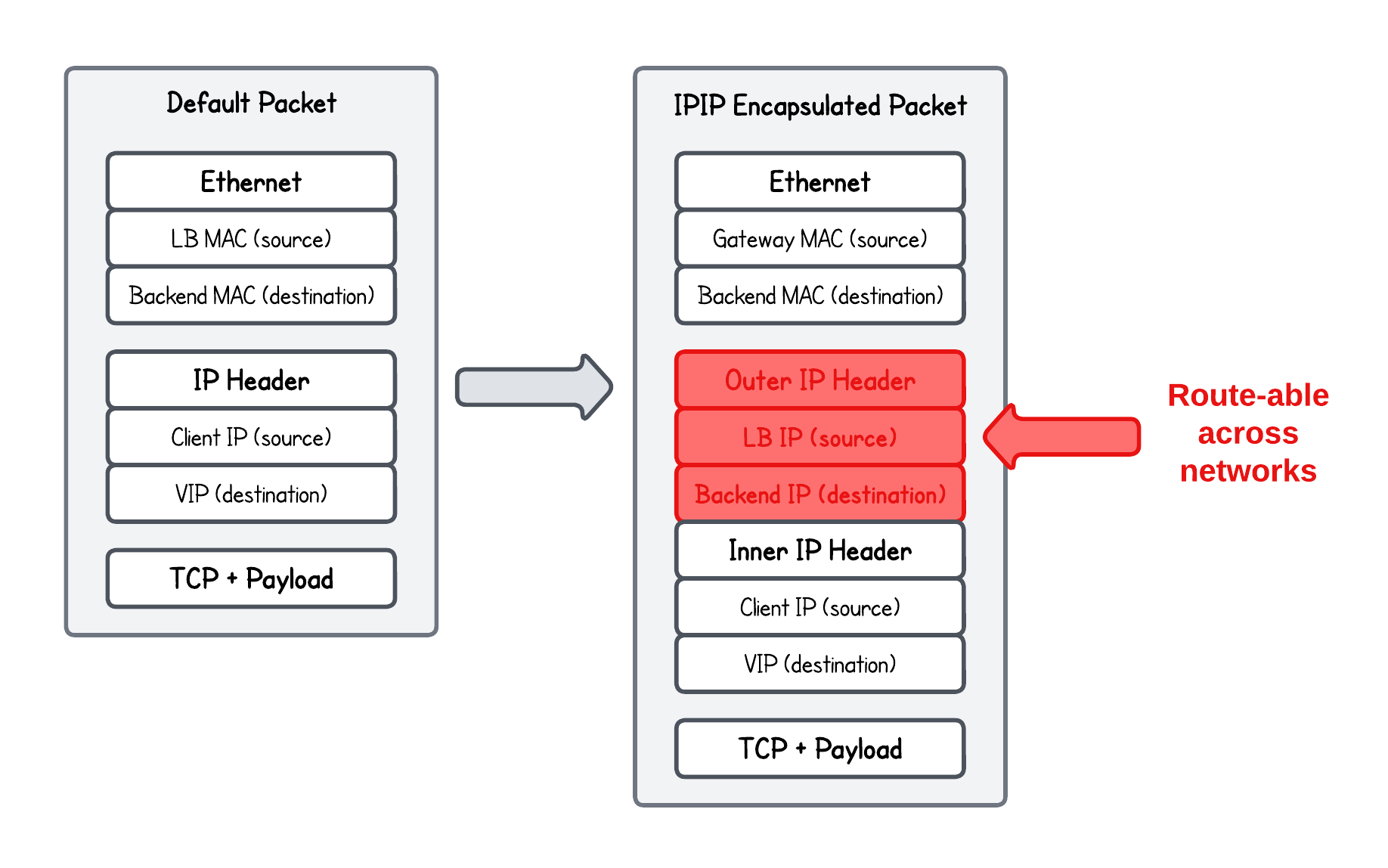
To understand how to achieve this, one needs to know how IP-in-IP (IPIP) encapsulation works.
In short, IP-in-IP encapsulation is a technique where one IP packet is wrapped inside another IP header, forming an outer and an inner IP header.
And the reason, why we need this is fairly simple.
The main limitation of L2 DSR was that if it tried to redirect traffic to a backend in a different L2 network, it would set the destination MAC address to the gateway’s interface (trying to exit current L2 network), and since only the VIP on the load balancer is advertised across the network, the gateway would send the packet back to the load balancer—because that’s the only route it knows for that VIP—causing a loop.
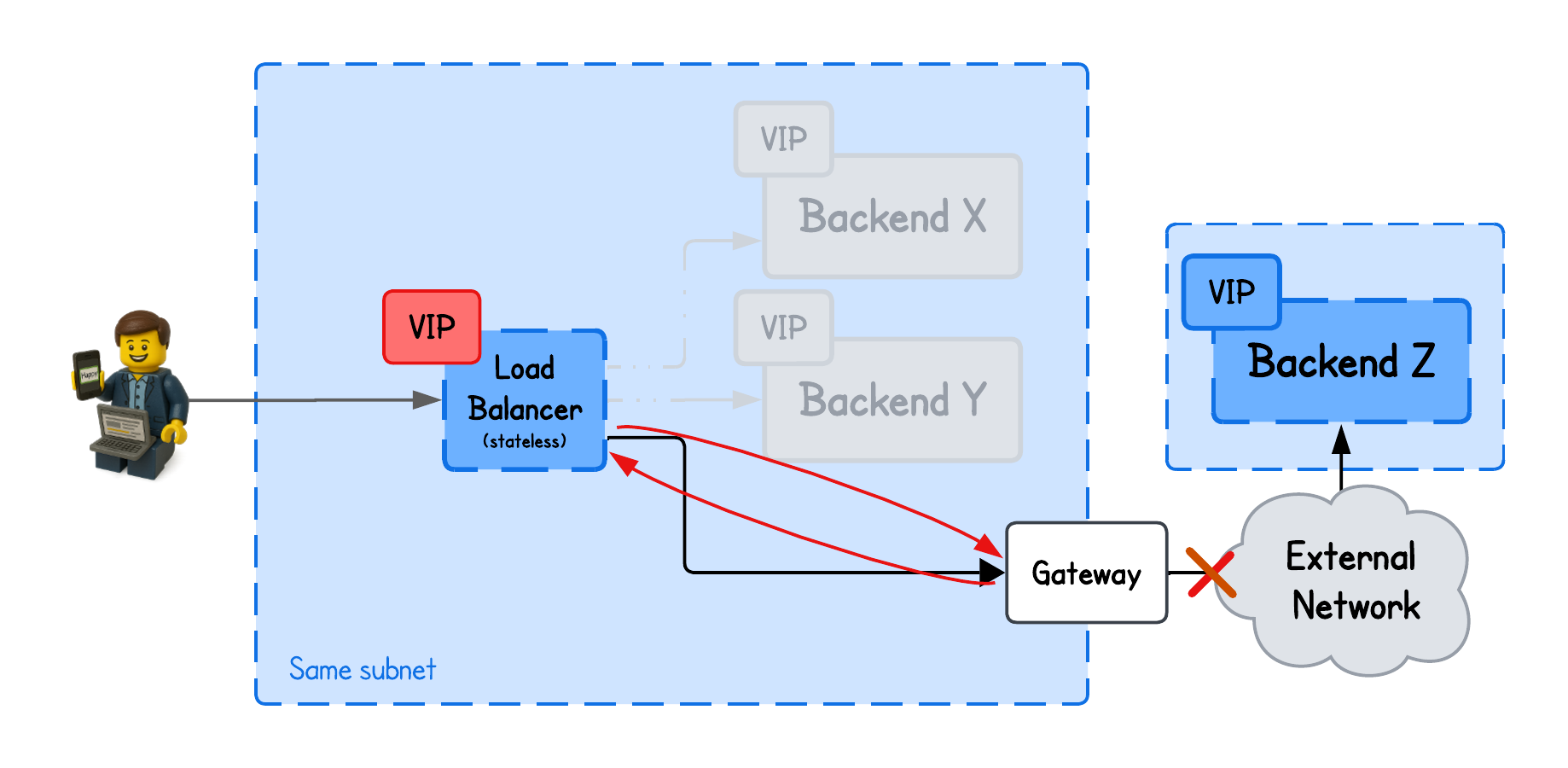
With IPIP (IP-in-IP) encapsulation, we solve this problem by wrapping the original IP packet inside another IP header where the outer IP header contains routable destination IPs, allowing the packet to traverse different networks.
Setting Up the Environment
To make this work in our playground, we first need to configure a VIP and enable IP forwarding on the load balancer (lb tab), just like we did in the L2 DSR coding lab:
sudo sysctl -w net.ipv4.ip_forward=1
sudo ip addr add 192.168.178.15/32 dev eth0
sudo ping -c1 172.16.0.10
sudo ping -c1 172.16.0.11
We also ping the backend node IPs to populate the ARP table, which is required for the bpf_fib_lookup helper function to work.
💡 If you need a quick reminder why this is necessary:
- Enabling IP forwarding allows the load balancer to route packets between interfaces.
- The
bpf_fib_lookup()helper function retrieves the next-hop MAC address from the kernel’s routing tables — either the backend’s MAC in the case of L2 DSR, or the gateway’s MAC in IPIP DSR.
Next, on both backend nodes (backend-01 and backend-02 tabs), configure the VIP and disable its ARP advertisement:
sudo ip addr add 192.168.178.15/32 dev lo
# Only reply to ARP requests if the target IP is assigned to the interface
# that received the request (prevents advertising the VIP on eth0)
sudo sysctl -w net.ipv4.conf.eth0.arp_ignore=1
# When sending ARP requests, use only addresses assigned to the outgoing interface
# (prevents the node from leaking the VIP as a source IP in ARP)
sudo sysctl -w net.ipv4.conf.eth0.arp_announce=2
💡 This is important, so no node knows the VIP exists on the backends; otherwise, clients could bypass the load balancer and establish a direct connection. We had described this in more details in the previous DSR L2 Load Balancing tutorial.
With that in place, the final step is to make sure our eBPF/XDP-based DSR IPIP load balancer encapsulates the packet before forwarding it.
// Choose backend using simple hashing
struct four_tuple_t four_tuple;
four_tuple.src_ip = ip->saddr;
four_tuple.dst_ip = ip->daddr;
four_tuple.src_port = tcp->source;
four_tuple.dst_port = tcp->dest;
four_tuple.protocol = IPPROTO_TCP;
__u32 key = xdp_hash_tuple(&four_tuple) % NUM_BACKENDS;
struct endpoint *backend = bpf_map_lookup_elem(&backends, &key);
if (!backend) {
return XDP_ABORTED;
}
// Perform a FIB lookup
struct bpf_fib_lookup fib = {};
int rc = fib_lookup_v4_full(ctx, &fib, ip->daddr, backend->ip,
bpf_ntohs(ip->tot_len));
if (rc != BPF_FIB_LKUP_RET_SUCCESS) {
log_fib_error(rc);
return XDP_ABORTED;
}
// Make room for the new outer IPv4 header (20 bytes) between ETH and inner IPv4
int adj = bpf_xdp_adjust_head(ctx, 0 - (int)sizeof(struct iphdr));
if (adj < 0) {
bpf_printk("Failed to adjust packet head");
return XDP_ABORTED;
}
// Recompute packet pointers after adjusting headed
void *new_data_end = (void *)(long)ctx->data_end;
void *new_data = (void *)(long)ctx->data;
// Re-parse Ethernet header
struct ethhdr *new_eth = new_data;
if ((void *)(new_eth + 1) > new_data_end) {
return XDP_ABORTED;
}
// Outer IPv4 header lives right after Ethernet
struct iphdr *outer = (void *)(new_eth + 1);
if ((void *)(outer + 1) > new_data_end) {
return XDP_ABORTED;
}
// Inner IPv4 header is now right after the new outer IP header
struct iphdr *inner = (void *)(outer + 1);
if ((void *)(inner + 1) > new_data_end) {
return XDP_ABORTED;
}
// Backend needs to have a virtual IP on the lo (same one as load balancer)
// The source IP is retained as client, so backend will respond directly to it
__builtin_memcpy(new_eth->h_source, fib.smac, ETH_ALEN);
__builtin_memcpy(new_eth->h_dest, fib.dmac, ETH_ALEN);
new_eth->h_proto = bpf_htons(ETH_P_IP);
// Build OUTER IPv4 header
__u16 inner_len = bpf_ntohs(inner->tot_len);
__u16 outer_len = (__u16)(inner_len + sizeof(struct iphdr));
outer->version = 4;
outer->ihl = 5; // 20 bytes
outer->tos = 0;
outer->tot_len = bpf_htons(outer_len);
outer->id = 0;
outer->frag_off = 0;
outer->ttl = 64;
outer->protocol = IPPROTO_IPIP;
// Retrieve LB real IP
__u32 lbkey = 0;
struct endpoint *lb = bpf_map_lookup_elem(&load_balancer, &lbkey);
if (!lb) {
return XDP_ABORTED;
}
outer->saddr = lb->ip; // use LB real IP as outer source
outer->daddr = backend->ip; // tunnel endpoint = backend node IP
outer->check = 0;
// Compute outer L3 checksum from scratch
outer->check = recalc_ip_checksum(outer);
💡 I’m leaving out other code details, such as hashing and packet rewriting, since they are exactly the same as in the L2 DSR tutorial. Make sure to check it out if you haven’t already, as it makes a lot of sense to learn both in this order.
And that's ALMOST it.
We must still instruct the backend nodes to decapsulate the received IPIP packets. Servers do not handle this by default, so we need to manually enable the IPIP tunnel interface to ensure the traffic is read correctly.
IPIP Packet Decapsulation
When the packet reaches the backend node, the backend node needs to decapsulate it — and this is handled by the ipip kernel module.
Why does it need to decapsulate the packet?
Since the packet sent from the load balancer to the backend node is an encapsulated IP header (inner) within another IP header (outer), the backend needs to "access" the inner IP header to figure out it points to its VIP on the localhost (lo).
It does this by decapsulating the packet.
Therefore, first load the ipip kernel module, enabling IP-in-IP tunneling support on the backends (backend-01 and backend-02 tabs):
sudo modprobe ipip
Then create a new IP-in-IP tunnel interface named ipip0 (in the backend-01 and backend-02 tabs):
sudo ip link add name ipip0 type ipip external
Now, to make this tunnel interface active so it can start receiving and sending packets (in the backend-01 and backend-02 tabs):
sudo ip link set up dev ipip0 # Bring the tunnel interface up
sudo ip address add 127.0.0.42/32 dev ipip0 # Assign a dummy local IP address to the tunnel device so the kernel considers it active (not used actually - that's why dummy!)
Finally, validate the configuration (in the backend-01 and backend-02 tabs), using:
ip -d link show dev ipip0
6: ipip0@NONE: <NOARP,UP,LOWER_UP> mtu 1480 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0 promiscuity 0 allmulti 0 minmtu 0 maxmtu 0
ipip external any remote any local any ttl inherit pmtudisc addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535 tso_max_size 65536 tso_max_segs 65535 gro_max_size 65536
And that’s all the magic there is — the same VIP configuration concepts apply to IPIP DSR as they did for L2 DSR (setting up the VIP and ensuring it doesn’t respond to ARP requests).
💡 While we could also use XDP/eBPF programs on the backend nodes to handle decapsulation, we will skip that for now to keep our focus strictly on the load balancer implementation.
Let's see it in action.
Running the Load Balancer
⚠️ Before moving on, make sure the VIP is configured on both the load balancer and the backend nodes as described above, and that the ARP table is populated on the load balancer.
Compile and run the load balancer (lb tab under lab directory) using:
go generate
go build
sudo ./lb -i eth0 -backends 172.16.0.10,172.16.0.11 -lb-ip 192.168.178.10
What are these input parameters?
-i: The network interface on which this XDP load balancer program will run.-backends: The list of backend IPs in this playground. You must provide exactly two backends, as simplified earlier for the basic hashing example.-lb-ip: The load balancer’s IP address, used as the source IP in the outer IP header. This could be automated, but we’re keeping the setup simple.
And run the HTTP Server binded to VIP (on the lo) on both backends (backend-01 and backend-02 tabs):
python3 -m http.server 8000 --bind 192.168.178.15
Now you can query the VIP from either client tab, using:
curl http://192.168.178.15:8000
And make sure that the HTTP server actually received the request from the client (IP at the beginning of the line):
10.0.0.20 - - [01/Jan/2026 16:03:45] "GET / HTTP/1.1" 200 -
Let's say you don't believe md, this actually led to request being routed through the load balancer and directly back to the client.
If you want to be sure, play-around with tcpdump or just verify it by inspecting the load balancers logs, using (in the "new" lb tab):
sudo bpftool prog trace
Congrats - you've came to the end of this tutorial 🎉
About the Author
Writes about
Frequently covers