Accelerating Transparent Ingress Proxy with eBPF and Envoy

In the previous lab we learned what role different features—such as eBPF TC programs, SO_ORIGINAL_DST, and SO_MARK—play in transparently redirecting traffic to Envoy between the client and the server application.
That said, putting a middleman like Envoy into the network path inevitably hurts the performance.
So the real question, then, is how much of this performance tax we can realistically eliminate—if any.
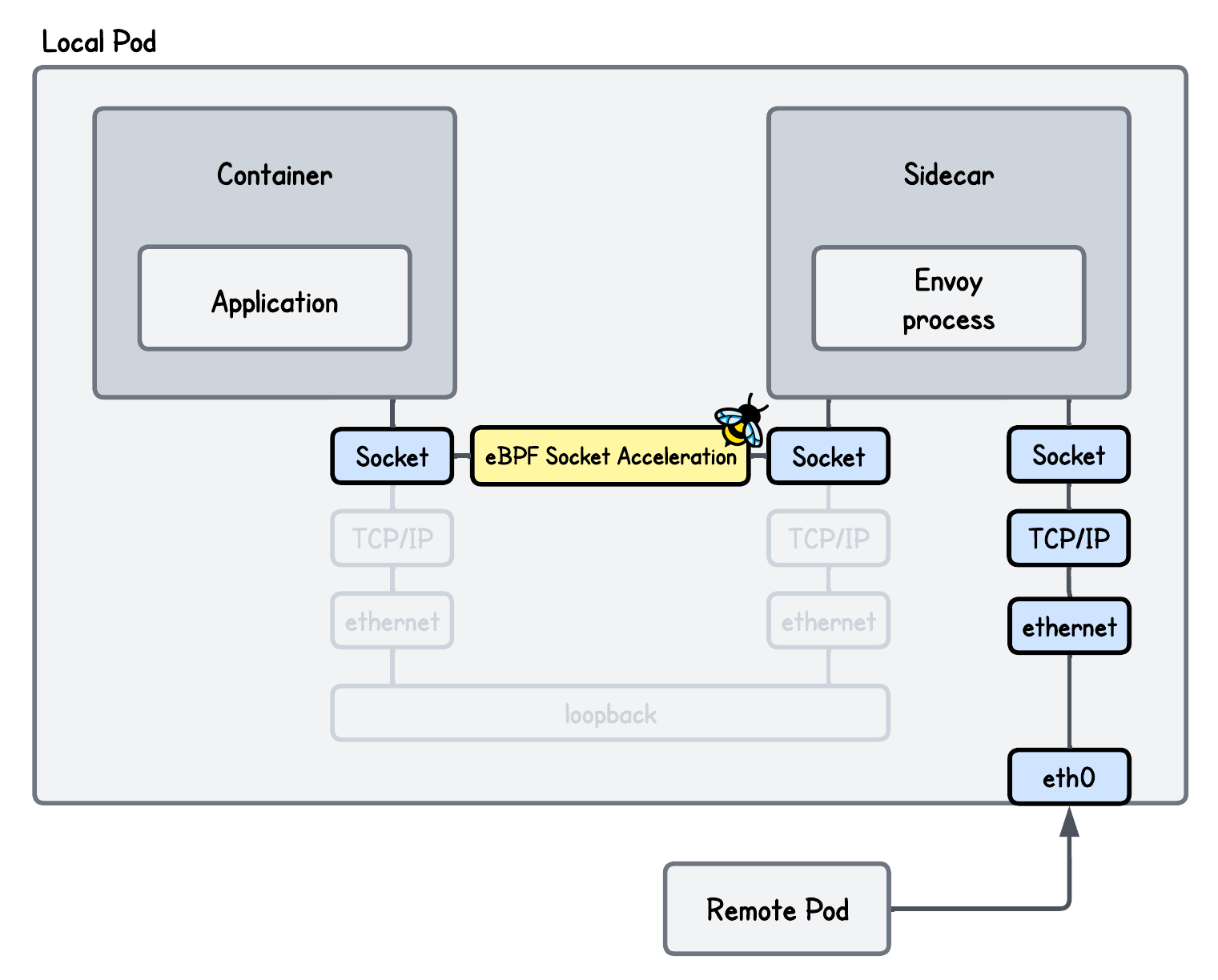
In this lab, we focus on optimizing transparent redirection on the receiving pod using eBPF socket acceleration. We show how eBPF can significantly speed up communication between the Envoy proxy and the application, mitigating much of the performance overhead introduced by the proxy.
The Bottleneck
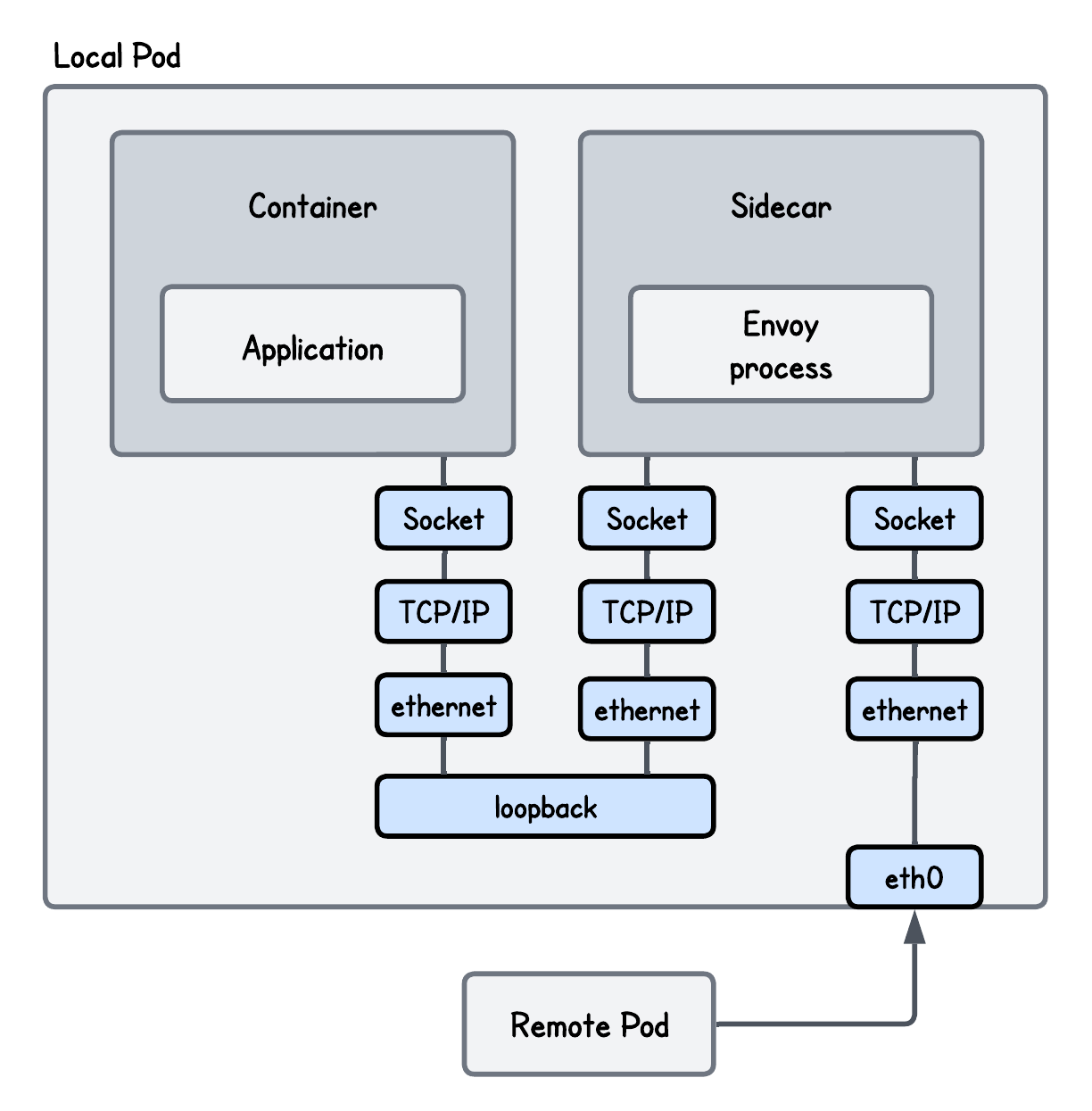
A side effect of introducing a transparent proxy like Envoy is that packets traverse the kernel networking stack twice, as well as connections being terminated, processed, and forwarded by the proxy.
Let's say you don't take my word for it - here are the benchmark results performed using iperf3 and sockperf comparing the setup with and without Envoy in-between.
![[object Object]](/content/files/tutorials/ebpf-envoy-ingress-acceleration-ad8d4111/__static__/merged-benchmark-envoy.png)
💡 Although the benchmark was run in a controlled environment, the absolute numbers are less meaningful because they depend on the specific setup; what really matters is the relative difference between the results.
So almost 20% lower network throughput and more than 2x larger network latency!
A lot of room for improvement and one way to optimize this setup is using eBPF socket acceleration.
Materials by an Independent Author
Extra content pack required to access this material