Transparent Egress Proxy with eBPF and Envoy

When you start learning how a service mesh works, one of the most fundamental concepts to understand is transparent traffic redirection.
Put simply, how can we place a proxy like Envoy in the network path between two services without requiring any changes on either side and without making the services even aware that the proxy exists?
In this lab, we focus on transparent egress traffic proxying on the sending Pod—that is, the client side. You'll learn how eBPF can be used to make the client think as if nothing exists in the network path, even though the traffic is being transparently intercepted by Envoy.
💡 I say transparent egress proxy because we intercept traffic originating from the client before it even leaves its Kubernetes Pod. In the next lab, we’ll complement this setup with a transparent ingress proxy, intercepting traffic on the server (receiving) side.
From iptables to eBPF Redirection
If you'd look back, when the service meshes were first introduced, most, if not all, projects were utilizing iptables to achieve the redirection to transparent proxies.
iptables has been around for more than 25 years and has grown into a powerful, feature-rich system. But if you've ever had to debug an iptables chain in high-density environments like Kubernetes, you'd quickly figure out it's just a nightmare.
Even a seemingly simple task like transparently redirecting traffic to a sidecar container (e.g. Envoy proxy in Kubernetes service mesh) involves many moving parts.
Let's take Istio Service Mesh and a client-side transparent redirection as an example:
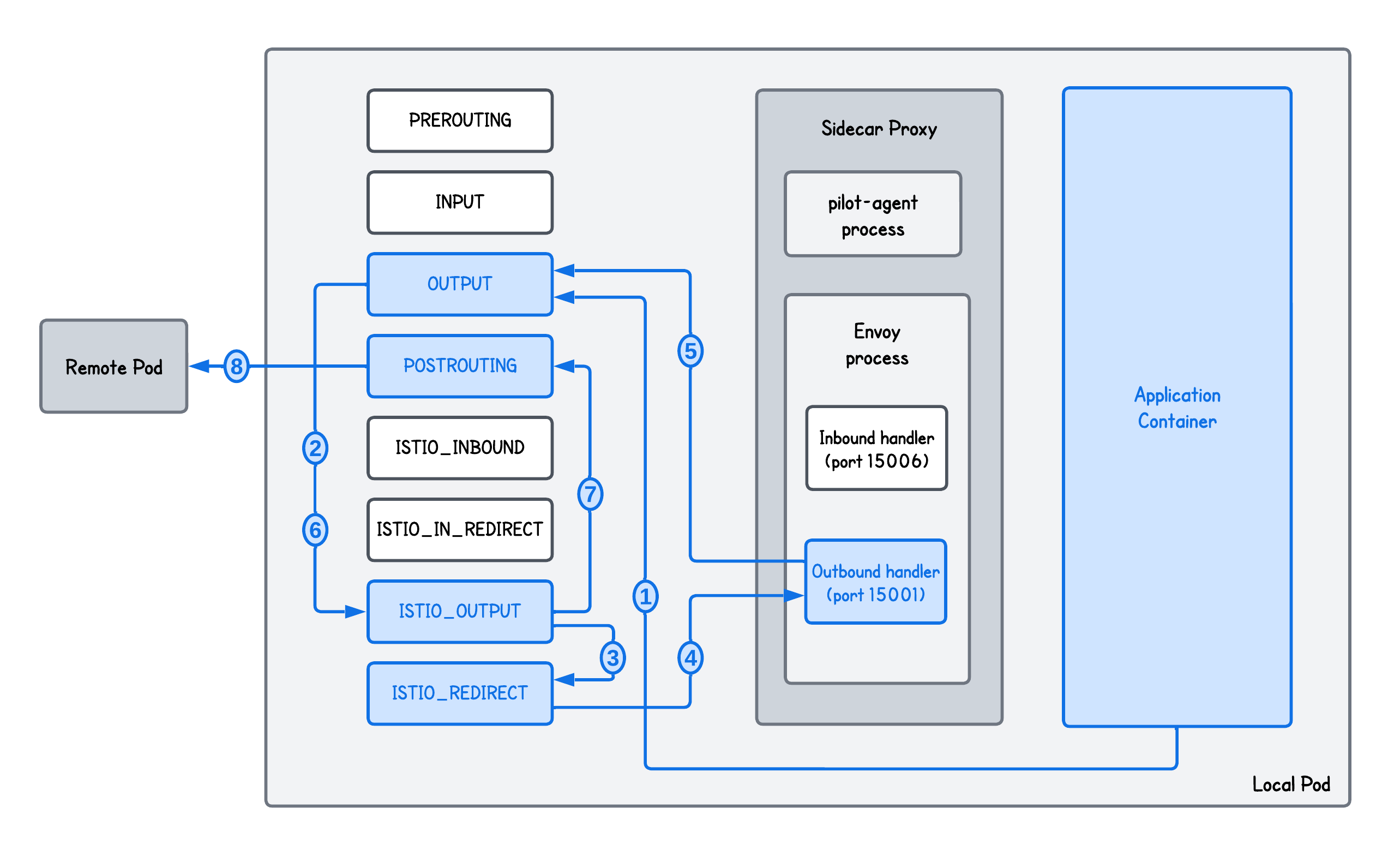
What is actually happening here?
In the transparent egress proxying using iptables:
- Step 1 - The Application Container sends a packet destined for a Remote Pod. Since this packet is generated locally, it first hits the OUTPUT iptables chain.
- Step 2 & 3 - The OUTPUT chain directs the packet to the ISTIO_OUTPUT chain that inspects the packet. If the traffic is not coming from the Envoy proxy itself, it passes the packet to the ISTIO_REDIRECT chain.
- Step 4 - ISTIO_REDIRECT performs a transparent redirection by changing the packet's destination port to 15001, where the Envoy Outbound Handler is listening.
- Step 5 - Envoy receives the packet, inspects it, identifies the original destination and initiates a new connection to the Remote Pod. This "new" packet hits the OUTPUT chain again.
- Step 6 & 7 - The OUTPUT chain again passes it through to the ISTIO_OUTPUT, which this time recognizes that the traffic is coming from the Envoy process and forwards it to the POSTROUTING chain.
- Step 8 - The packet passes through POSTROUTING and exits the Local Pod, heading toward the Remote Pod.
And this is only for handling traffic sent from the client Kubernetes Pod - the traffic passes through Pod-level iptables rules, the transparent proxy, back through iptables, and finally out of the Pod.
Not to mention also that iptables performance relies on sequential rule processing—evaluating each rule one by one against observed traffic—so the more rules you have, the lower the performance.
So can we do better?
In fact we can using eBPF and that's exactly what we will do.
eBPF Implementation Breakdown
At a high level, transparent egress redirection requires the following steps to occur:
- Redirect clients' egress traffic targeting the remote Pod to the Envoy proxy sidecar
- Store the original destination before rewriting it and configure Envoy to recover it and establish an upstream connection to it
To redirect clients' egress traffic to Envoy using eBPF, we can simply just rewrite the destination IP and port on the clients' egress traffic:
SEC("cgroup/connect4")
int redirect(struct bpf_sock_addr *ctx) {
...
// Redirect the connection to the Envoy proxy (hardcoded for simplicity)
ctx->user_ip4 = bpf_htonl(0x7f000001); // proxy IP (127.0.0.1)
ctx->user_port = (__u32)bpf_htons(ENVOY_PORT); // proxy port
bpf_printk("Redirecting connection to Envoy proxy...");
return 1;
}
More information about this eBPF Program Type
This is an BPF_PROG_TYPE_CGROUP_SOCK_ADDR eBPF program type that can be used to capture and alter socket address parameters during socket operations such as connect(), bind(), sendmsg() and so on.
We explicitly attach it to the cgroup/connect4 attachment point, which triggers whenever a socket (inside the cgroup this program is attached to) attempts to establish an IPv4 connection.
connect4Link, err := link.AttachCgroup(link.CgroupOptions{
Path: CGROUP_PATH,
Attach: ebpf.AttachCGroupInet4Connect, // <- Attachment Point
Program: objs.Redirect,
})
If this is confusing, it helps to look at how client-server connections work at the "syscall level".
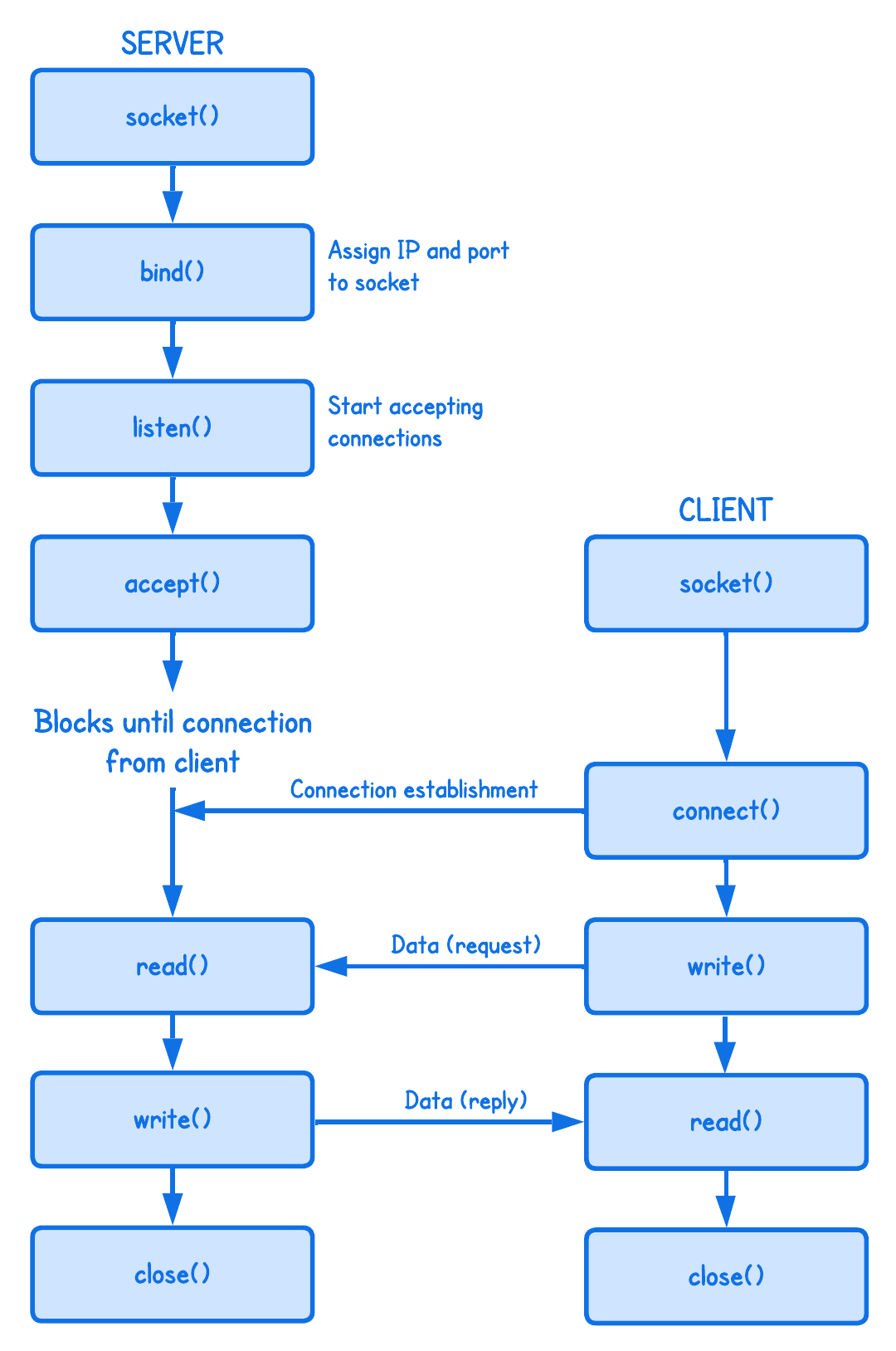
In other words, our eBPF program intercepts the connect() syscall and changes the destination address and redirects it to our Envoy proxy process.
While this does replace the destination the client is connecting to by alterating the connect() syscall, we also need to figure out how Envoy can recover the original destination (client initially intended to connect to) and initiate a connection to it.
This is where Envoy Original Destination Listener Filter comes in:
static_resources:
listeners:
- name: listener_http
...
# This filter queries the Linux kernel using getsockopt() to recover the actual destination IP and
# port that were overwritten when the connection was redirected to Envoy
listener_filters:
- name: envoy.filters.listener.original_dst
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.listener.original_dst.v3.OriginalDst
...
filter_chains:
- filters:
- name: envoy.filters.network.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
stat_prefix: ingress_http
use_remote_address: true
route_config:
name: echo_route
# Forward the request to the original-dst cluster
virtual_hosts:
- name: backend
domains: ["*"]
routes:
- match:
prefix: "/"
route:
cluster: original-dst
...
clusters:
# This "special" cluster type tells Envoy to ignore static host lists and instead
# open an upstream connection to the specific address recovered by the listener filter
- name: original-dst
type: ORIGINAL_DST
lb_policy: CLUSTER_PROVIDED
...
Whenever sockets are transparently redirected using iptables, the Envoy Original Destination Listener Filter tries to recover the original destination by reading SO_ORIGINAL_DST socket option of the downstream connection.
💡 SO_ORIGINAL_DST is a socket option that allows a program to retrieve the original destination IP address and port of a connection before it was modified by NAT or redirection.
But wait—our setup doesn’t use iptables. So how can this help us?
Even if Envoy would try (in our setup) to retrieve the original destination (using getsockopt()), it would fail since no such redirection has actually occured (with iptables).
Could eBPF assist us here, anyhow?
In fact, yes!
Internally, Envoy uses the getsockopt() system call to read the SO_ORIGINAL_DST socket option of the client connection.
So technically, we can just intercept the getsockopt() system call using cgroup SockOpt eBPF program and rewrite the original destination it recovers.
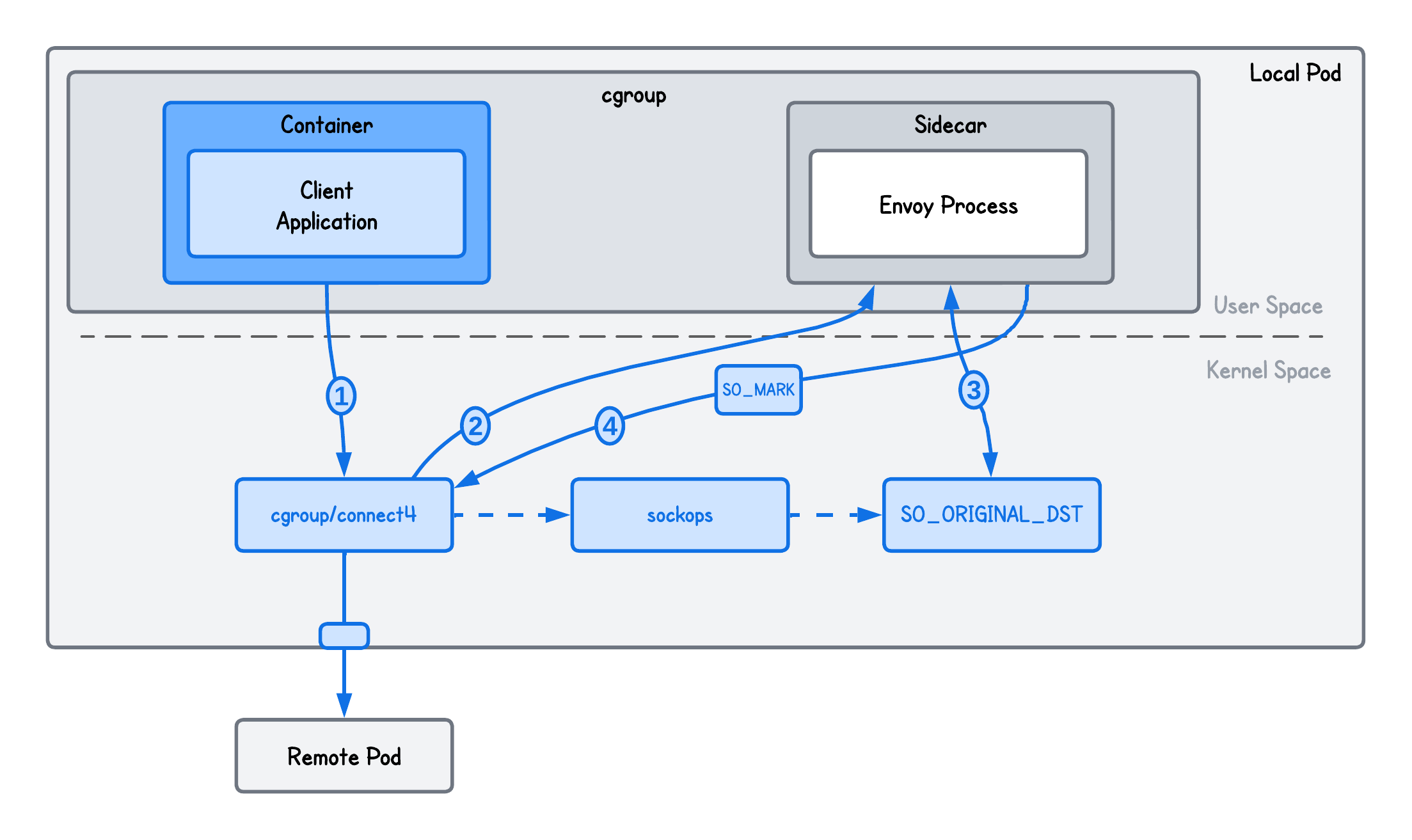
To do so, we need to store the original destination before rewriting it in the cgroup/connect4 eBPF program and "pass" it down to our cgroup SockOpt eBPF program (cgroup/getsockopt).
SEC("cgroup/connect4")
int redirect(struct bpf_sock_addr *ctx) {
...
// Store original destination under the clients' socket cookie
// This is necessary so we can rewrite the original destination in our cgroup/getsockopt eBPF program
__u64 cookie = bpf_get_socket_cookie(ctx);
struct dest_socket sock = {0};
sock.dst_addr = ctx->user_ip4;
sock.dst_port = ctx->user_port;
bpf_map_update_elem(&map_socks, &cookie, &sock, 0);
...
}
SEC("sockops")
int cg_sock_ops(struct bpf_sock_ops *ctx) {
...
// Triggered on the client (active) side once the connection is established.
if (ctx->op == BPF_SOCK_OPS_ACTIVE_ESTABLISHED_CB) {
// Returns the client's socket cookie because the BPF_SOCK_OPS_ACTIVE_ESTABLISHED_CB operation
// triggers specifically on the "active" side (the initiator) of the connection.
__u64 cookie = bpf_get_socket_cookie(ctx);
// We need to map the clients' source port to the socket cookie, because the bpf_get_socket_cookie() helper function
// is not available in the cgroup/getsockopt while the clients' source port is.
struct dest_socket *sock = bpf_map_lookup_elem(&map_socks, &cookie);
if (sock) {
__u16 src_port = ctx->local_port;
bpf_map_update_elem(&map_ports, &src_port, &cookie, 0);
bpf_printk("Recorded client source port...");
}
}
...
}
// This is triggered when the proxy queries the original destination client was trying to reach
SEC("cgroup/getsockopt")
int cg_sock_opt(struct bpf_sockopt *ctx) {
...
// Get the clients' source port so we can get the clients' socket cookie (and consequentily the original destination)
// It's actually sk->dst_port because from Envoy perspective the "Destination" is the client that connected to it
__u16 src_port = bpf_ntohs(ctx->sk->dst_port);
__u64 *cookie = bpf_map_lookup_elem(&map_ports, &src_port);
if (!cookie) return 1;
// Using the cookie, retrieve the original destination from map_socks
struct dest_socket *sock = bpf_map_lookup_elem(&map_socks, cookie);
if (!sock) return 1;
...
// Rewrite the original destination retrieved by the getsockopt syscall
sa->sin_addr.s_addr = sock->dst_addr;
sa->sin_port = sock->dst_port;
...
}
💡 This implementation only captures and redirects IPv4 connections, while it could be easily extended to IPv6 but left-out for simplicity.
Why do we then need the sockops eBPF program?
However you want to turn this around, since we have decided to provide the original destination to the Envoy proxy by overidding the getsockopt syscall (that the Envoy Original Destination Listener Filter internally makes), we need to somehow be able to achieve that in our cgroup/getsockopt eBPF program.
The way we make this possible is:
- Store the original destination in the
map_sockseBPF map, keyed by the client’s socket cookie, before rewriting it incgroup/connect4 - Because the socket cookie is not available in
cgroup/getsockopt, use asockopseBPF program as a bridge that stores the socket cookie keyed by the client’s ephemeral source port in themap_portsmap - Since the source port is available in
cgroup/getsockopt, retrieve the original destination by first resolving the socket cookie frommap_portsand then looking up the original destination inmap_socks
It's more like a "workaround" rather than how we ought to do things, because we have to work with the kernel data that these eBPF programs "expose" to us.
Here's an image to help clarify the exchange of information between these three programs.
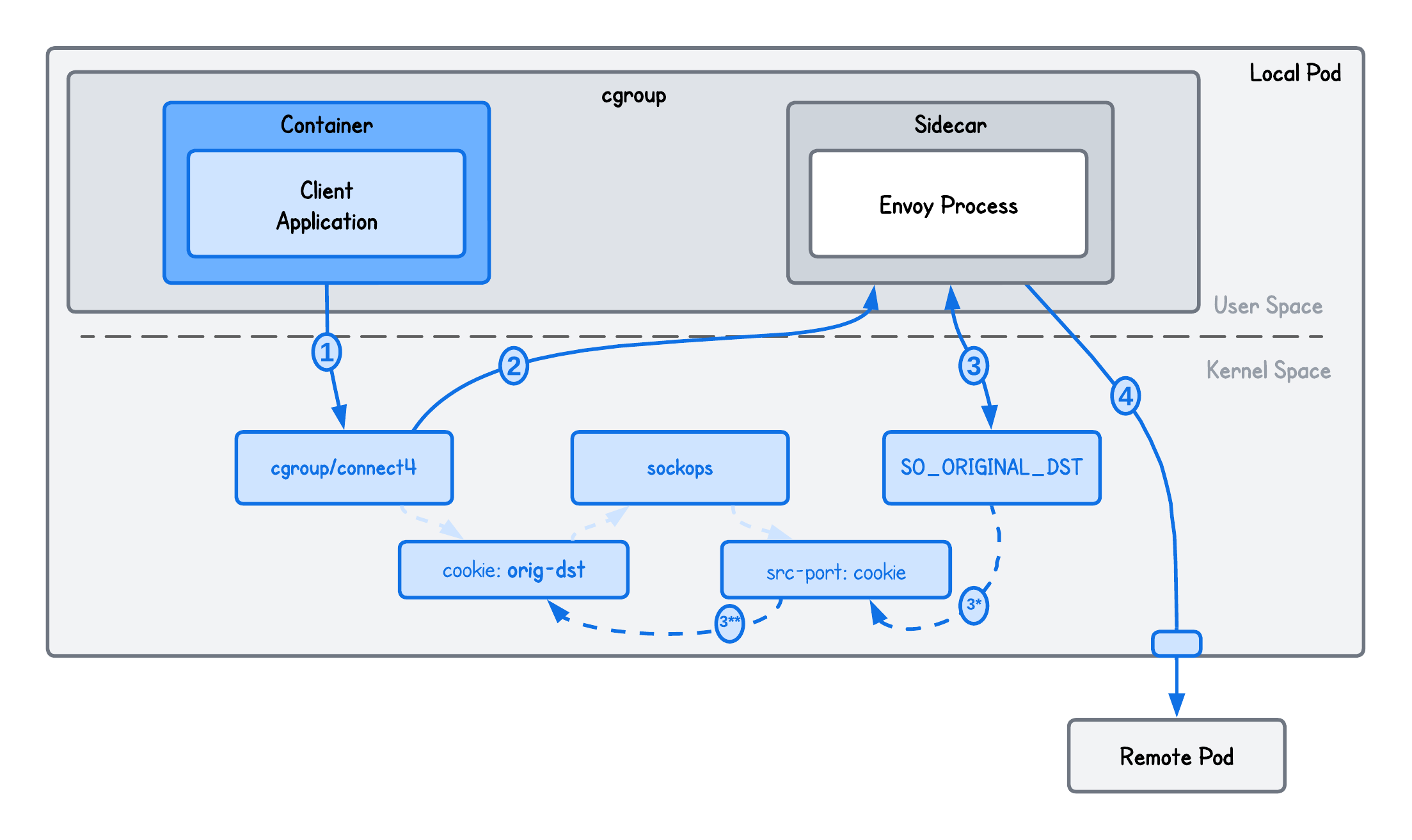
But is this really all there is? Not really.
Avoiding Re-Redirection to Envoy
The problem with this setup is that whenever the connect() syscall is triggered in the cgroup to which our cgroup/connect4 eBPF program is attached to, the connection will be redirected to Envoy.
Meaning, if the Envoy process itself is part of the same cgroup, its upstream connections to the original destination will also trigger connect() and be redirected back to Envoy again, resulting in an infinite redirection loop.
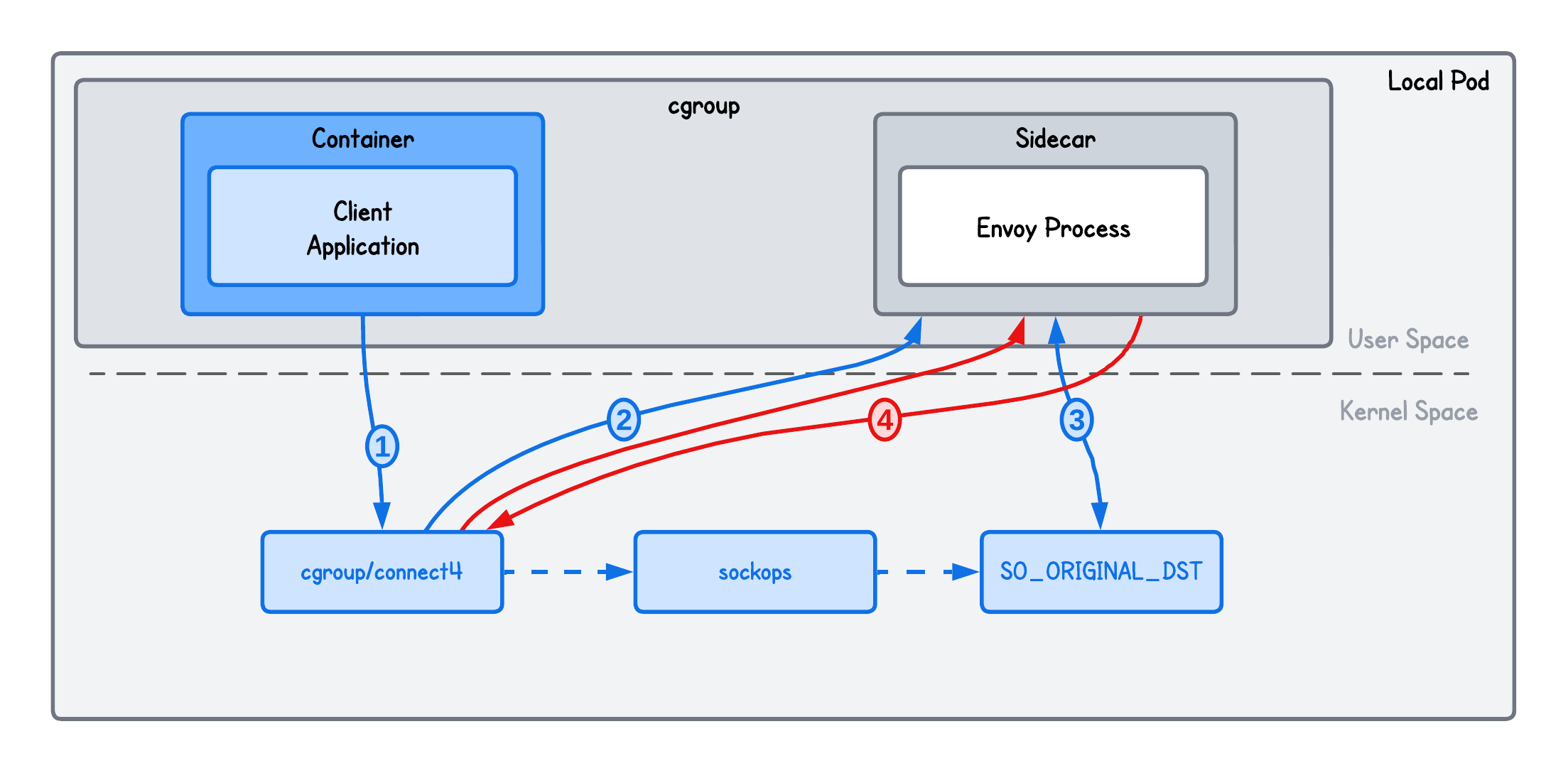
Confused by what I mean by “upstream” and “downstream” connections?
I use the term connection loosely, but here’s what I mean in this context:
- Downstream connection: a client connecting to Envoy
- Upstream connection: a connection from Envoy to the (original) destination
One way to avoid this is to place Envoy outside the cgroup where the cgroup/connect4 eBPF program is attached.
But let's consider that we can't afford that. This means we need a way to configure the eBPF program so that it does not redirect upstream connections initiated by Envoy itself.
This is where SO_MARK can help us.
Linux kernel allow us to configure the SO_MARK socket option on the sockets, and we can also do that in Envoy:
...
clusters:
# This "special" cluster type tells Envoy to ignore static host lists and instead
# open an upstream connection to the specific address recovered by the listener filter
- name: original-dst
type: ORIGINAL_DST
lb_policy: CLUSTER_PROVIDED
# Append the SO_MARK to the upstream connection to avoid re-redirection
upstream_bind_config:
socket_options:
- level: 1 # SOL_SOCKET
name: 36 # SO_MARK (Linux)
int_value: 4242
state: STATE_PREBIND
💡 With the upstream_bind_config.socket_options config we set a SO_MARK with value 4242 (arbitrarily chosen) on every upstream connection.
Once the SO_MARK is set on the upstream connections, we can check for the presence of this mark in our eBPF cgroup/connect4 program (before redirecting) using:
SEC("cgroup/connect4")
int redirect(struct bpf_sock_addr *ctx) {
// Don't redirect traffic coming from Envoy!
if (ctx->sk && ctx->sk->mark == SO_MARK) return 1;
...
Since our cgroup/connect4 eBPF program captures both the client and the Envoy proxy connections (because they share the same cgroup in this artificial example), only the client connection is redirected. The Envoy-initiated connection is skipped because it has SO_MARK set.
This eBPF redirection implementation will now in fact work.
An alternative approach
One could technically also avoid this problem by avoiding re-redirection based on Envoy PID:
- Retrive the Envoy PID using
pgrep envoy - Provide this value to our eBPF program through the eBPF map
- And compare it against the
bpf_get_current_pid_tgid >> 32
__u64 pid_tgid = bpf_get_current_pid_tgid();
__u32 curr_tgid = pid_tgid >> 32;;
// This prevents the proxy from proxying itself
__u64 *pid = bpf_map_lookup_elem(&pid_map, &curr_tgid);
if (pid) {
return TC_ACT_OK;
}
But this isn't really a viable solution since one would need to make sure whenever Envoy restart that it's corresponding PID is updated in the eBPF map.
And there could be several seconds between Envoy restarting and finally updating it's PID stored in the eBPF map. Several seconds of broken connections, which can be quite problematic depending upon your requirements.
We're almost done - let's see it in action.
Running the Transparent Egress Proxy
This simple playground has two machines on two different networks:
clientin network10.0.0.20/16serverin network192.168.178.10/24gatewaybetween networks192.168.178.2/24and10.0.0.2/16
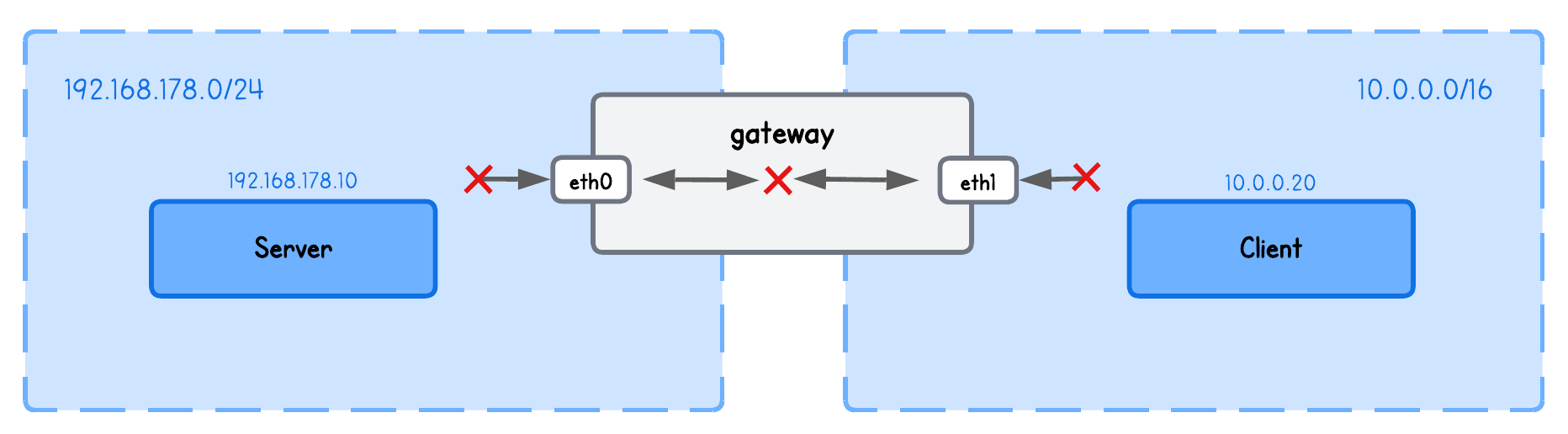
💡 While the theory above focused on how this concept fits into a Kubernetes service mesh to avoid adding complexity, it’s equally valid to think of Pods as nodes and containers as processes in this playground. Which is what we based our system on without including the Kubernetes complexities.
First, start an HTTP server on the server node (server tab):
python3 -m http.server
Then, run the Envoy proxy on the client node (client tab, in the lab directory):
sudo envoy -c envoy.yaml
Build and run the eBPF transparent redirection program (in a new client tab, in the lab directory):
go generate
go build
sudo ./tproxy
Lastly, Query the server from the client node (open a new client tab):
curl http://192.168.178.10:8000
To verify the redirection actually worked, check the Envoy logs (client tab where you run envoy) to see that the request was indeed captured.
{"duration_ms":4,"method":"GET","protocol":"HTTP/1.1","path":"/","start_time":"2026-01-18T12:12:07.544Z","response_flags":"-","response_code":200,"downstream_remote":"127.0.0.1:56764","upstream_cluster":"original-dst","host_header":"192.168.178.10:8000","virtual_cluster":null,"request_id":"4a65958e-df88-4ee6-a1de-c7ba2c3e4677","upstream_host":"192.168.178.10:8000","route_name":null}
Or view the eBPF program logs (client tab) using:
sudo bpftool prog trace
From here, we could build on this by configuring different Envoy policies—defining what’s allowed, what’s not, and more—but I’ll leave that for another time.
More importantly, since we’re aiming to build a minimal service mesh, interception also needs to happen on the server/receiving side.
But more about this in the next lab.
About the Author
Writes about
Frequently covers