Docker Containers vs. Kubernetes Pods - Taking a Deeper Look
A container could have become a lightweight VM replacement.
However, the most widely used form of containers, popularized by Docker and later standardized by OCI,
encourages you to have just one process service per container.
Such an approach has a few significant upsides -
increased isolation, simplified horizontal scaling, higher reusability, etc.
However, this design also has a major drawback - in the real world, virtual machines rarely run just one service.
Thus, the container abstraction might often be too limited for a fully-featured VM replacement.
While Docker were trying to offer workarounds to create multi-service containers, Kubernetes made a bolder step and chose as its smallest deployable unit not a single but a group of cohesive containers, called a Pod.
For engineers with prior VM or bare-metal experience, it should be relatively easy to grasp the idea of Pods, or so it may seem... 🙈
One of the first things you learn when beginning working with Kubernetes is that each Pod is assigned a unique IP address and a hostname. Furthermore, containers within a Pod can communicate with each other via localhost. Thus, it quickly becomes clear that a Pod resembles a server in miniature.
After a while, though, you realize that every container in a Pod gets an isolated filesystem and that from inside one container, you don't see files and processes of the other containers of the same Pod. So, maybe a Pod is not a tiny little server but just a group of containers with shared network devices?
But then you learn that containers in one Pod can communicate via shared memory and other typical Linux IPC means! So, probably the network namespace is not the only shared thing...
That last finding was the final straw for me, and I decided to deep dive and see with my own eyes:
- How Pods are implemented under the hood;
- What the actual difference between a Pod and a Container is;
- What it would take to create a Pod using standard Docker commands.
Sounds interesting? Then join me on the journey! At the very least, it may help you solidify your Linux, Docker, and Kubernetes skills.
The OCI Runtime Spec doesn't limit container implementations to only Linux containers, i.e., the ones implemented with namespaces and cgroups. However, unless otherwise is stated explicitly, the word container in this article refers to this rather traditional form.
Examining a container
Let's start our guinea-pig container:
docker run --name foo --rm -d --memory='512MB' --cpus='0.5' nginx:alpine
Inspecting container's namespaces
Firstly, it'd be interesting to see what isolation primitives were created when the container started.
Here is how you can find the container's namespaces:
NGINX_PID=$(pgrep --oldest nginx)
sudo lsns -p ${NGINX_PID}
NS TYPE NPROCS PID USER COMMAND
...
4026532253 mnt 3 1269 root nginx: master process nginx -g daemon off;
4026532254 uts 3 1269 root nginx: master process nginx -g daemon off;
4026532255 ipc 3 1269 root nginx: master process nginx -g daemon off;
4026532256 pid 3 1269 root nginx: master process nginx -g daemon off;
4026532258 net 3 1269 root nginx: master process nginx -g daemon off;
4026532319 cgroup 3 1269 root nginx: master process nginx -g daemon off;
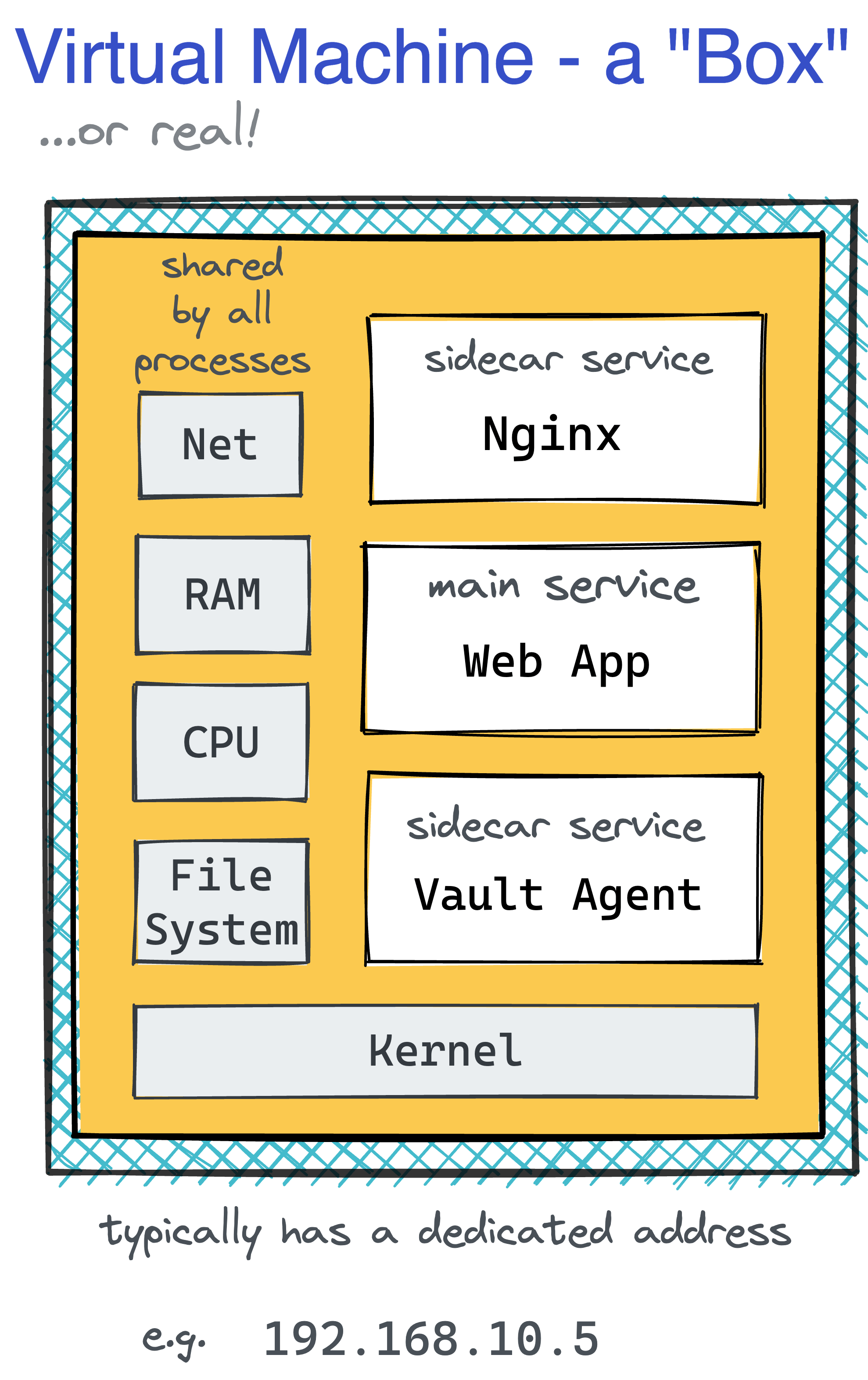
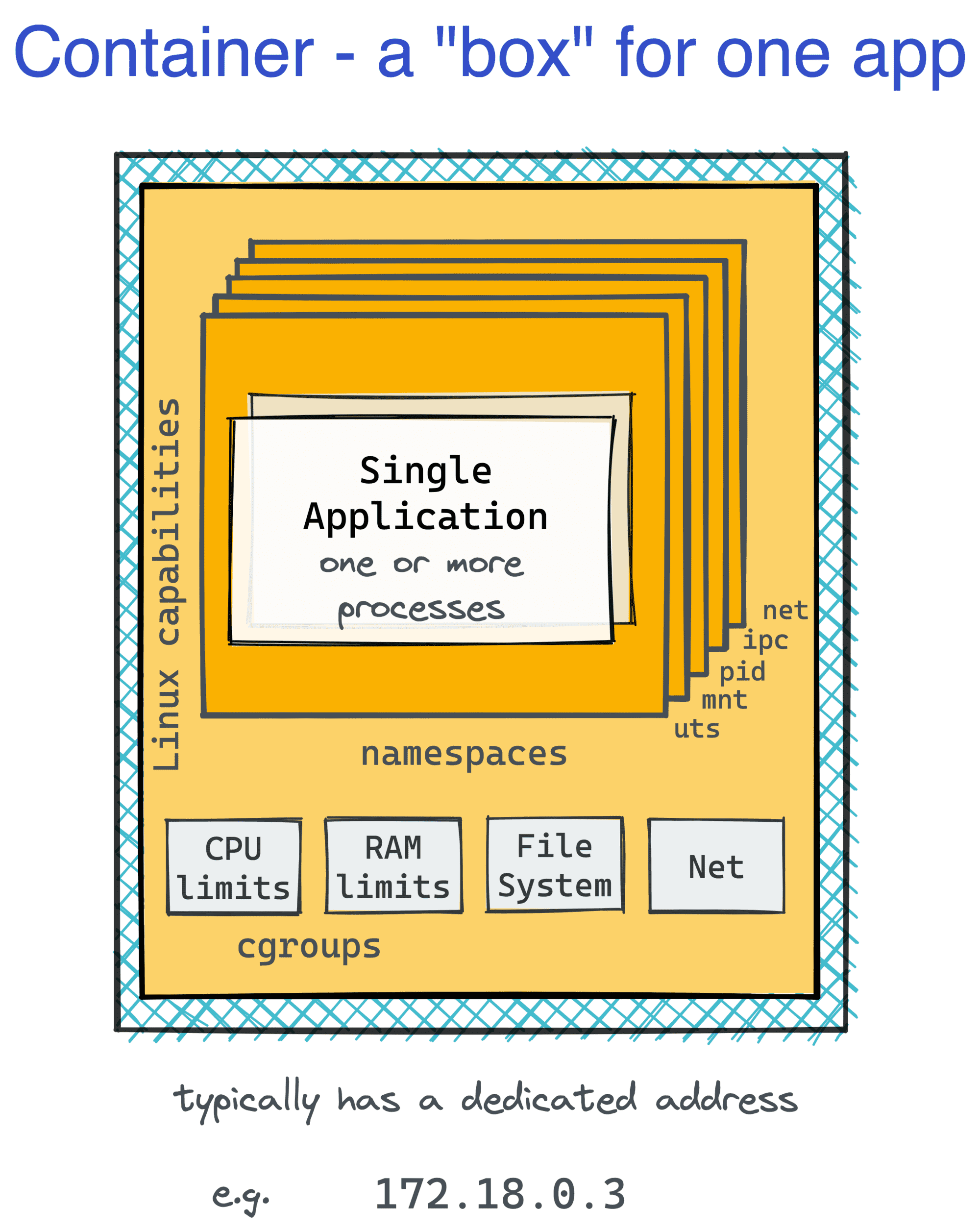
The namespaces used to isolate our nginx container are:
- mnt (Mount) - the container has an isolated mount table.
- uts (UNIX Time-Sharing) - the container is able to have its own hostname and domain name.
- ipc (Interprocess Communication) - processes inside the container can communicate via system-level IPC only to processes inside the same container.
- pid (Process ID) - processes inside the container are only able to see other processes inside the same container or inside the same pid namespace.
- net (Network) - the container gets its own set of network devices, IP protocol stacks, port numbers, etc.
- cgroup (Cgroup) - the container has its own virtualized view of the cgroup filesystem (not to be confused with cgroup mechanism itself).
Notice how the User namespace wasn't used! The OCI Runtime Spec mentions the user namespace support.
However, while Docker can use this namespace for its containers,
it doesn't do it by default due to the inherent limitations and extra operational complexity that it may add.
Thus, the root user in a container is likely the root user from your host system. Beware!
Level up your Server Side game — Join 30,000 engineers who receive insightful learning materials straight to their inbox
Another namespace on the list that requires a special callout is cgroup. It took me a while to understand that the cgroup namespace is not the same as the cgroups mechanism. Cgroup namespace just gives a container an isolated view of the cgroup pseudo-filesystem (which is discussed below).
Inspecting container's cgroups
Linux namespaces make processes inside a container think they run on a dedicated machine. However, not seeing any neighbors doesn't mean being fully protected from them. Some hungry neighbors can accidentally consume an unfair share of the host's resources.
Cgroups to the rescue!
The cgroup limits for a given process can be checked by examining its node in the cgroup pseudo-filesystem (cgroupfs) that is usually mounted at /sys/fs/cgroup.
But first, we need to figure out the path to the cgroupfs subtree for the process of interest:
sudo systemd-cgls --no-pager
Control group /:
-.slice
...
│
└─system.slice
...
│
├─docker-866191e4377b052886c3b85fc771d9825ebf2be06f84d0bea53bc39425f753b6.scope …
│ ├─1269 nginx: master process nginx -g daemon off;
│ └─1314 nginx: worker process
...
Then list the cgroupfs subtree:
ls -l /sys/fs/cgroup/system.slice/docker-$(docker ps --no-trunc -qf name=foo).scope/
...
-rw-r--r-- 1 root root 0 Sep 27 11:12 cpu.max
-r--r--r-- 1 root root 0 Sep 27 11:12 cpu.stat
-rw-r--r-- 1 root root 0 Sep 27 11:12 cpu.weight
...
-rw-r--r-- 1 root root 0 Sep 27 11:51 io.max
-r--r--r-- 1 root root 0 Sep 27 11:12 io.stat
...
-rw-r--r-- 1 root root 0 Sep 27 11:12 memory.high
-rw-r--r-- 1 root root 0 Sep 27 11:12 memory.low
-rw-r--r-- 1 root root 0 Sep 27 11:12 memory.max
-rw-r--r-- 1 root root 0 Sep 27 11:12 memory.min
...
-r--r--r-- 1 root root 0 Sep 27 11:42 pids.current
-r--r--r-- 1 root root 0 Sep 27 11:51 pids.events
-rw-r--r-- 1 root root 0 Sep 27 11:12 pids.max
And to see the memory limit in particular, one needs to read the value in the memory.max file:
cat /sys/fs/cgroup/system.slice/docker-$(docker ps --no-trunc -qf name=foo).scope/memory.max
536870912 # Exactly 512MB that were requested at the container start.
Interesting that starting a container without explicitly setting any resource limits configures a cgroup slice for it anyway.
I haven't really checked, but my guess is that while CPU and RAM consumption is unrestricted by default,
cgroups might be used to limit some other resource consumption and device access (e.g., /dev/sda and /dev/mem) from inside a container.
Here is how the container can be visualized based on the above findings:
Examining a Pod
Now, let's take a look at Kubernetes Pods. To keep the Containers to Pods comparison fair, the Pod examination will be done on a Kubernetes cluster that uses the same underlying container runtime as Docker does - containerd/runc.
Much like with containers, the implementation of Pods can vary.
For instance, when Kata Containers are used as the CRI runtime
(via setting the runtimeClassName attribute on the Pod spec),
Pods become true virtual machines!
Expectedly, VM-based Pods will differ in implementation and capabilities from Pods implemented with traditional Linux containers.
The following two-container Pod will be examined:
apiVersion: v1
kind: Pod
metadata:
name: foo
spec:
containers:
- name: app
image: nginx:alpine
ports:
- containerPort: 80
resources:
limits:
memory: "256Mi"
- name: sidecar
image: curlimages/curl:8.3.0
command: ["/bin/sleep", "3650d"]
resources:
limits:
memory: "128Mi"
You can start the Pod with the following command:
kubectl apply -f pod.yaml
Inspecting Pod's containers
The Pod inspection should be done on the Kubernetes cluster node where this Pod is running.
Using the kube-01 tab on the right, let's try finding the Pod's processes:
ps auxf
PID USER ELAPSED CMD
...
1748 root 01:16 /var/lib/rancher/k3s/data/ab2055bc72380bad965b219e8
1769 65535 01:15 \_ /pause
1801 root 01:15 \_ nginx: master process nginx -g daemon off;
1846 message+ 01:15 | \_ nginx: worker process
1847 message+ 01:15 | \_ nginx: worker process
1859 _apt 01:15 \_ /bin/sleep 3650d
Based on the similarity of the uptime and the common parent, the above three (top-level) processes were likely created during the Pod startup.
That's interesting because in the manifest, only two containers, nginx and sleep, were requested.
It's possible to cross-check the above finding using the containerd command-line client called ctr:
sudo ctr --namespace=k8s.io containers ls
CONTAINER IMAGE RUNTIME
1c0d4c94188aa docker.io/library/nginx:alpine io.containerd.runc.v2
3f2b45521b479 docker.io/curlimages/curl:8.3.0 io.containerd.runc.v2
fe99217fab7c5 docker.io/rancher/mirrored-pause:3.6 io.containerd.runc.v2
...
Indeed, three new containers were created by the Kubernetes container runtime - nginx, sleep, and pause.
At the same time, crictl - another command-line client compatible with any Kubernetes CRI runtime - shows just two containers:
sudo crictl ps
CONTAINER IMAGE ... NAME POD ID POD
d74ad720df223 ead0a4a53df89 coredns bf8d6b16f6c10 coredns-6799fbcd5-6xksq
3f2b45521b479 99f2927cb384d sidecar fe99217fab7c5 foo
1c0d4c94188aa 433dbc17191a7 app fe99217fab7c5 foo
But notice how the POD ID field above matches the pause container ID from the ctr's output!
Well, seems like the Pod has an auxiliary container. So, what is it for?
I'm not aware of any OCI Runtime Spec equivalent for Pods. So, when I'm not satisfied with the information provided by the Kubernetes API spec, I usually go directly to the Kubernetes Container Runtime Interface (CRI) protobuf file:
// kubelet expects any compatible container runtime
// to implement the following gRPC methods:
service RuntimeService {
...
rpc RunPodSandbox(RunPodSandboxRequest) returns (RunPodSandboxResponse) {}
rpc StopPodSandbox(StopPodSandboxRequest) returns (StopPodSandboxResponse) {}
rpc RemovePodSandbox(RemovePodSandboxRequest) returns (RemovePodSandboxResponse) {}
rpc PodSandboxStatus(PodSandboxStatusRequest) returns (PodSandboxStatusResponse) {}
rpc ListPodSandbox(ListPodSandboxRequest) returns (ListPodSandboxResponse) {}
rpc CreateContainer(CreateContainerRequest) returns (CreateContainerResponse) {}
rpc StartContainer(StartContainerRequest) returns (StartContainerResponse) {}
rpc StopContainer(StopContainerRequest) returns (StopContainerResponse) {}
rpc RemoveContainer(RemoveContainerRequest) returns (RemoveContainerResponse) {}
rpc ListContainers(ListContainersRequest) returns (ListContainersResponse) {}
rpc ContainerStatus(ContainerStatusRequest) returns (ContainerStatusResponse) {}
rpc UpdateContainerResources(UpdateContainerResourcesRequest) returns (UpdateContainerResourcesResponse) {}
rpc ReopenContainerLog(ReopenContainerLogRequest) returns (ReopenContainerLogResponse) {}
// ...
}
message CreateContainerRequest {
// ID of the PodSandbox in which the container should be created.
string pod_sandbox_id = 1;
// Config of the container.
ContainerConfig config = 2;
// Config of the PodSandbox. This is the same config that was passed
// to RunPodSandboxRequest to create the PodSandbox. It is passed again
// here just for easy reference. The PodSandboxConfig is immutable and
// remains the same throughout the lifetime of the Pod.
PodSandboxConfig sandbox_config = 3;
}
So, Pods are actually defined in terms of sandboxes and containers that can be started in these sandboxes.
The sandbox thingy manages some common for all Pod's containers resources, and the pause container is started during the RunPodSandbox() call.
A little bit of Internet searching reveals that this container has just an idling process inside.
Inspecting Pod's namespaces
Here is what the (relevant) namespaces look like on the cluster node:
sudo lsns
NS TYPE NPROCS PID USER COMMAND
...
4026532333 net 5 1769 65535 /pause
4026532397 mnt 1 1769 65535 /pause
4026532398 uts 5 1769 65535 /pause
4026532399 ipc 5 1769 65535 /pause
4026532400 pid 1 1769 65535 /pause
4026532401 mnt 3 1801 root nginx: master process nginx -g daemon off;
4026532402 pid 3 1801 root nginx: master process nginx -g daemon off;
4026532403 cgroup 3 1801 root nginx: master process nginx -g daemon off;
4026532404 mnt 1 1859 _apt /bin/sleep 3650d
4026532405 pid 1 1859 _apt /bin/sleep 3650d
4026532406 cgroup 1 1859 _apt /bin/sleep 3650d
Much like the Docker container in the first part, the pause container gets five namespaces - net, mnt, uts, ipc, and pid.
But apparently, nginx and sleep containers get just by three namespaces - mnt, pid, and cgroup. How come?
Turns out, lsns might not be the best tool to check process' namespaces.
Instead, to check the namespaces used by a certain process, the /proc/${PID}/ns path can be referred:
# 1801 is the PID of the nginx container
sudo ls -l /proc/1801/ns
...
lrwxrwxrwx 1 root root 0 sep 28 12:00 cgroup -> 'cgroup:[4026532403]'
lrwxrwxrwx 1 root root 0 Sep 28 12:00 ipc -> 'ipc:[4026532399]'
lrwxrwxrwx 1 root root 0 Sep 28 12:00 mnt -> 'mnt:[4026532401]'
lrwxrwxrwx 1 root root 0 Sep 28 12:00 net -> 'net:[4026532333]'
lrwxrwxrwx 1 root root 0 Sep 28 12:00 pid -> 'pid:[4026532402]'
lrwxrwxrwx 1 root root 0 Sep 28 12:00 uts -> 'uts:[4026532398]'
...
# 1859 is the PID of the sleep container
sudo ls -l /proc/1859/ns
...
lrwxrwxrwx 1 _apt messagebus 0 Sep 28 12:00 cgroup -> 'cgroup:[4026532406]'
lrwxrwxrwx 1 _apt messagebus 0 Sep 28 12:00 ipc -> 'ipc:[4026532399]'
lrwxrwxrwx 1 _apt messagebus 0 Sep 28 12:00 mnt -> 'mnt:[4026532404]'
lrwxrwxrwx 1 _apt messagebus 0 Sep 28 12:00 net -> 'net:[4026532333]'
lrwxrwxrwx 1 _apt messagebus 0 Sep 28 12:00 pid -> 'pid:[4026532405]'
lrwxrwxrwx 1 _apt messagebus 0 Sep 28 12:00 uts -> 'uts:[4026532398]'
...
While it might be tricky to notice, the nginx and sleep containers actually reuse the net, uts, and ipc namespaces of the pause container!
Again, this can be cross-checked with crictl:
# 1c0d4c94188aa is the ID of the nginx container
sudo crictl inspect 1c0d4c94188aa | jq .info.runtimeSpec.linux.namespaces
[
{
"type": "pid"
},
{
"type": "ipc",
"path": "/proc/1769/ns/ipc"
},
{
"type": "uts",
"path": "/proc/1769/ns/uts"
},
{
"type": "mount"
},
{
"type": "network",
"path": "/proc/1769/ns/net"
},
{
"type": "cgroup"
}
]
# 3f2b45521b479 is the ID of the sleep container
sudo crictl inspect 3f2b45521b479 | jq .info.runtimeSpec.linux.namespaces
[
{
"type": "pid"
},
{
"type": "ipc",
"path": "/proc/1769/ns/ipc"
},
{
"type": "uts",
"path": "/proc/1769/ns/uts"
},
{
"type": "mount"
},
{
"type": "network",
"path": "/proc/1769/ns/net"
},
{
"type": "cgroup"
}
]
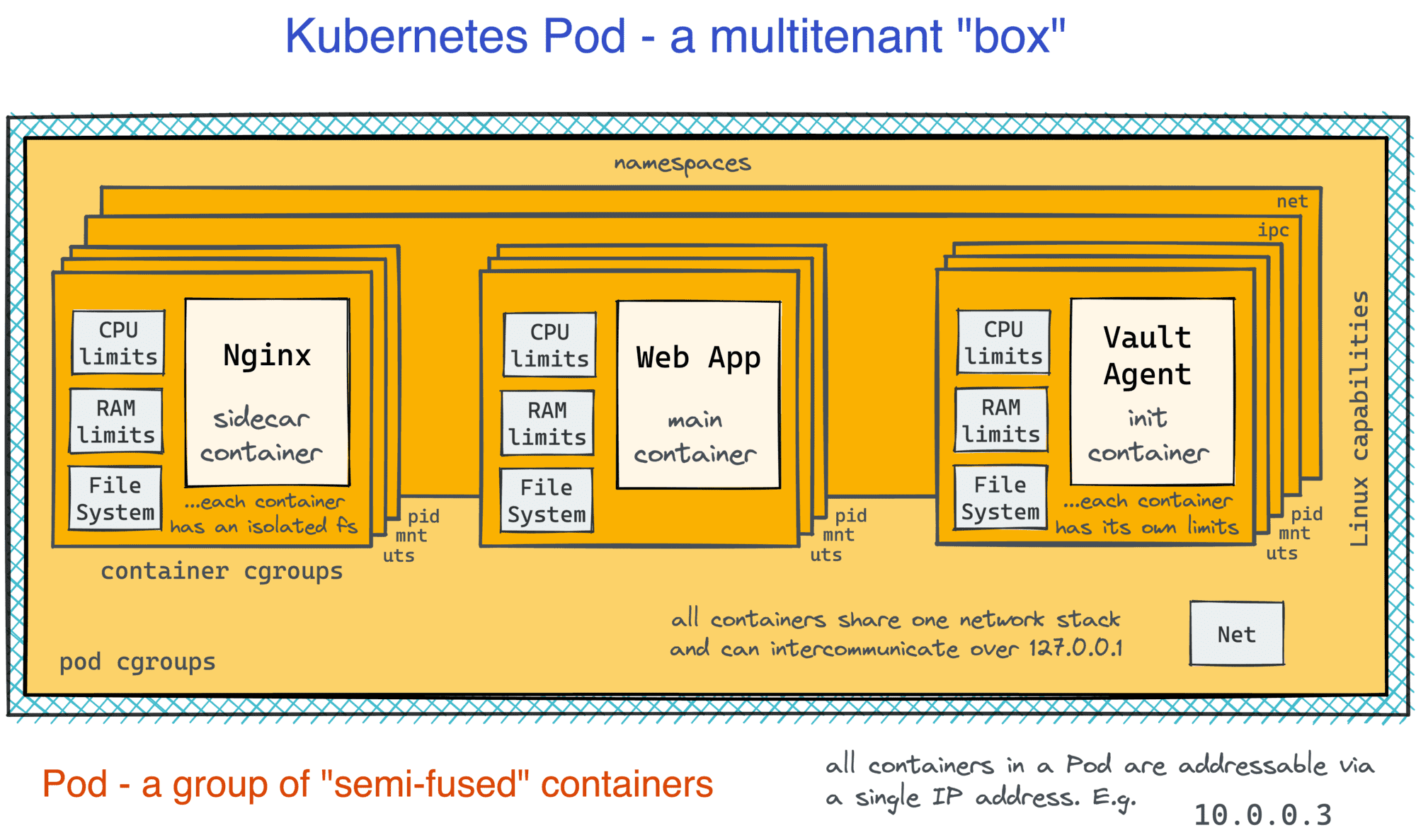
I think the above findings perfectly explain the ability of containers in the same Pod:
- To talk to each other
- via localhost and/or
- using IPC means (shared memory, message queues, etc.)
- To have a shared domain and hostname.
However, after seeing how all these namespaces are freely reused between containers, I started to suspect that the default boundaries can be shacked.
And indeed, a more thorough read of the Pod API spec showed that with the shareProcessNamespace flag set to true Pod's containers will have four common namespaces instead of the default three.
But there was a more shocking finding - hostIPC, hostNetwork, and hostPID flags can make the containers use the corresponding host's namespaces!
Interesting that the CRI API spec seems to be even more flexible. At least syntactically, it allows scoping the net, pid, and ipc namespaces to either CONTAINER, POD, or NODE. So, hypothetically, a Pod where containers cannot talk to each other via localhost can be constructed 🙈
Inspecting Pod's cgroups
Ok, what's up with Pod's cgroups? systemd-cgls can nicely visualize the cgroups hierarchy:
sudo systemd-cgls --no-pager
Control group /:
-.slice
...
└─kubepods.slice
└─kubepods-burstable.slice
...
└─kubepods-burstable-pode88e5109_51f9_4f39_8d99_ada6fb281137.slice
├─cri-containerd-1c0d4c94188aa402db8751db1301de1d3adcc6739ee2ca78c6738273ee8251a7.scope …
│ ├─1801 nginx: master process nginx -g daemon off;
│ ├─1846 nginx: worker process
│ └─1847 nginx: worker process
├─cri-containerd-fe99217fab7c597c40f10b8086dfa2978394e9942b53d66569441b5b7d7d4ea0.scope …
│ └─1769 /pause
└─cri-containerd-3f2b45521b479bc1c07a8eebf9409e244d5fbf9eb431156d250a37f492599604.scope …
└─1859 /bin/sleep 3650d
Seems like the Pod itself gets a parent node, and every container can be tweaked separately as well. This matches my expectations based on the fact that in the Pod manifest, resource limits can be set for every container in the Pod individually.
At this moment, a Pod in my head looks something like this:
Implementing Pods with Docker
If a Pod under the hood is implemented as a bunch of semi-fused containers with a common cgroup parent, will it be possible to reproduce a Pod-like construct using Docker?
Recently I already tried doing something similar to make multiple containers listen on the same socket, and I know that Docker allows creating a container that reuses an existing network namespace with the docker run --network container:<other-container-name> syntax. But I also know that the OCI Runtime Spec defines only create and start commands. So, when you execute a command inside an existing container with docker exec <existing-container> <command>, you actually run, i.e., create then start, a completely fresh container that just happens to reuse all the namespaces of the target container (proofs 1 & 2). It makes me pretty confident the Pods can be reproduced using the standard Docker commands.
Firstly, a parent cgroup entry needs to be configured.
Luckily, these days, it's relatively easy to accomplish, thanks to systemd.
For the sake of brevity, I'll configure only the cpu and memory cgroup controllers:
sudo tee /etc/systemd/system/mypod.slice <<EOF
[Unit]
Description=My Pod Slice
[Slice]
MemoryLimit=512M
CPUQuota=50%
EOF
sudo systemctl daemon-reload
sudo systemctl start mypod.slice
Check if the slice was actually created:
sudo systemd-cgls --no-pager --all
Control group /:
-.slice
...
├─mypod.slice
...
Secondly, a sandbox container needs to be created:
docker run -d --rm \
--name mypod_sandbox \
--cgroup-parent mypod.slice \
--ipc 'shareable' \
alpine sleep infinity
Lastly, we need to start the payload containers reusing the namespaces of the sandbox container:
# app (nginx)
docker run -d --rm \
--name app \
--cgroup-parent mypod.slice \
--network container:mypod_sandbox \
--ipc container:mypod_sandbox \
nginx:alpine
# sidecar (sleep)
docker run -d --rm \
--name sidecar \
--cgroup-parent mypod.slice \
--network container:mypod_sandbox \
--ipc container:mypod_sandbox \
curlimages/curl sleep 365d
Have you noticed which namespace I omitted?
Right, I couldn't share the uts namespace between containers.
Seems like this possibility is not exposed currently in the docker run command.
Well, that's a pity, of course. But apart from the uts namespace, it's a success!
The cgroups look much like the ones created by Kubernetes itself:
sudo systemd-cgls --no-pager --all
This time, the slice will have several active processes listed:
Control group /:
-.slice
...
├─mypod.slice
│ ├─docker-575fd1bbc28340fbd37c35374dd4ef8a91d796cf4abc2e97eaac42981ae2058a.scope …
│ │ └─1480 sleep infinity
│ ├─docker-c36d2f83cf53ebe5354f7a6f60770b8728772e6c788979d8a35338da102a2fd6.scope …
│ │ └─1312 sleep infinity
│ ├─docker-48dff78e59361aea6876385aa0677c1ad949b0951cb97b9cf7d1e8fba991dc3e.scope …
│ │ └─1669 sleep 365d
│ └─docker-85b436943b55fdb4666d384711ad3577f41c0d03e58987c639633a35a37bacf4.scope …
│ ├─1599 nginx: master process nginx -g daemon off;
│ └─1635 nginx: worker process
The global list of namespaces also looks familiar:
sudo lsns
NS TYPE NPROCS PID USER COMMAND
...
4026532322 mnt 1 1480 root sleep infinity
4026532323 uts 1 1480 root sleep infinity
4026532324 ipc 4 1480 root sleep infinity
4026532325 pid 1 1480 root sleep infinity
4026532327 net 4 1480 root sleep infinity
4026532385 cgroup 1 1480 root sleep infinity
4026532386 mnt 2 1599 root nginx: master process nginx -g daemon off;
4026532387 uts 2 1599 root nginx: master process nginx -g daemon off;
4026532388 pid 2 1599 root nginx: master process nginx -g daemon off;
4026532389 cgroup 2 1599 root nginx: master process nginx -g daemon off;
4026532390 mnt 1 1669 _apt sleep 365d
4026532391 uts 1 1669 _apt sleep 365d
4026532392 pid 1 1669 _apt sleep 365d
4026532393 cgroup 1 1669 _apt sleep 365d
And the app (nginx) and sidecar (curl) containers seems to share the ipc and net namespaces:
# app container
sudo ls -l /proc/1599/ns
lrwxrwxrwx 1 root root 0 Sep 28 13:09 cgroup -> 'cgroup:[4026532389]'
lrwxrwxrwx 1 root root 0 Sep 28 13:09 ipc -> 'ipc:[4026532324]'
lrwxrwxrwx 1 root root 0 Sep 28 13:09 mnt -> 'mnt:[4026532386]'
lrwxrwxrwx 1 root root 0 Sep 28 13:09 net -> 'net:[4026532327]'
lrwxrwxrwx 1 root root 0 Sep 28 13:09 pid -> 'pid:[4026532388]'
lrwxrwxrwx 1 root root 0 Sep 28 13:09 uts -> 'uts:[4026532387]'
...
# sidecar container
sudo ls -l /proc/1669/ns
lrwxrwxrwx 1 _apt messagebus 0 Sep 28 13:09 cgroup -> 'cgroup:[4026532393]'
lrwxrwxrwx 1 _apt messagebus 0 Sep 28 13:09 ipc -> 'ipc:[4026532324]'
lrwxrwxrwx 1 _apt messagebus 0 Sep 28 13:09 mnt -> 'mnt:[4026532390]'
lrwxrwxrwx 1 _apt messagebus 0 Sep 28 13:09 net -> 'net:[4026532327]'
lrwxrwxrwx 1 _apt messagebus 0 Sep 28 13:09 pid -> 'pid:[4026532392]'
lrwxrwxrwx 1 _apt messagebus 0 Sep 28 13:09 uts -> 'uts:[4026532391]'
...
Yay! We just (almost) created a Pod using only the standard docker run command 🎉
Summarizing
Containers and Pods are alike. Under the hood, they heavily rely on Linux namespaces and cgroups. However, Pods aren't just groups of containers. A Pod is a self-sufficient higher-level construct. All Pod's containers run on the same machine (cluster node), their lifecycle is synchronized, and mutual isolation is weakened to simplify the inter-container communication. This makes Pods much closer to traditional VMs, bringing back the familiar deployment patterns like sidecar or client-side service proxy.
Resources
- Kubernetes pod vs container: Multi-container pods and container communication - a good technical read.
- Tracing the path of network traffic in Kubernetes - touches upon Pods vs. Containers from the networking standpoint.
Practice
About the Author
Ivan Velichko
Ivan is the creator of iximiuz Labs and a long-time tech blogger and educator with a traditional focus on server-side tech and containers.
Writes about
Frequently covers