Kubernetes Pod Debugging Part 1 - Startup & Scheduling Issues

Kubernetes Pod Debugging Part 1: Startup & Scheduling Issues
Welcome to Part 1 of the Pod Debugging challenge! In Kubernetes, Pods are the smallest deployable units, representing one or more containers running together. However, things don't always go smoothly. This challenge presents Pods with common configuration errors, and your mission is to investigate and fix them using standard kubectl commands.
Understanding Pod Status and Common Errors
Before you begin, let's review some key concepts:
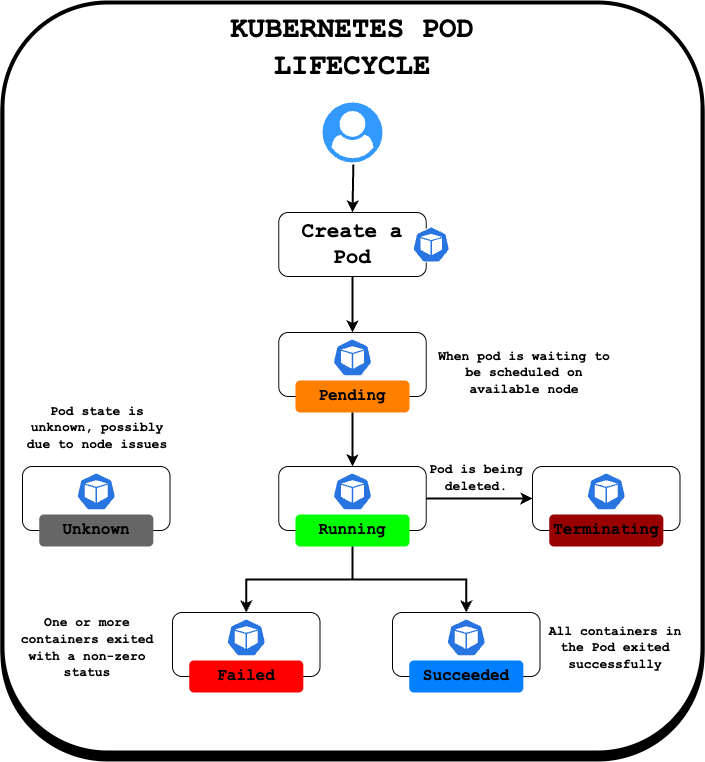
- Pod Phases: A Pod goes through several phases in its lifecycle:
Pending: The Pod has been accepted by Kubernetes, but one or more containers are not yet ready to run (e.g., image pulling, waiting for scheduling).Running: The Pod has been bound to a node, and all its containers have been created. At least one container is still running, or is in the process of starting or restarting.Succeeded: All containers in the Pod have terminated successfully (exit code 0) and will not be restarted.Failed: All containers in the Pod have terminated, and at least one container terminated in failure (non-zero exit code or killed by the system).Unknown: The state of the Pod could not be obtained, typically due to a communication error with the node hosting the pod.
- Common Container Statuses/Reasons: Within the
RunningorPendingphases, containers might show specific reasons for problems:ImagePullBackOff/ErrImagePull: Kubernetes cannot pull the specified container image (typo, non-existent tag, registry auth error).CrashLoopBackOff: The container starts, crashes, and Kubernetes keeps trying to restart it in a loop. This indicates a problem inside the container (faulty command, application error).ContainerCreating: The container is being created, often involves pulling the image if not present. Delays here might point to image pull issues.
- Scheduling Issues: If a Pod stays
Pendingand events mention scheduling failures, it often relates to:Resource Constraints: Not enough CPU/Memory on any node (Not covered in this Part 1).Node Selectors/Affinity: Rules preventing the pod from running on available nodes.Taints and Tolerations: Nodes might repel pods that don't tolerate their taints (Not covered in this Part 1).
You'll encounter some of these issues in the pods deployed for this challenge.
The initial (broken) YAML definitions for the challenge pods (pod-01.yaml, pod-02.yaml, pod-03.yaml) have been saved in the /home/laborant/challenge/ directory. You can inspect these files to understand the original configuration or modify them if you choose the delete/recreate approach to fixing the pods.
If you face Docker Hub rate limits, please try to use the following images (which have been pre-pulled into the lab environment) when fixing or creating pods in this challenge:
nginx:latestubuntu:latestalpine:latestbusybox:latesthttpd:latest
Let's get started!
First, investigate the pod named pod-01. It doesn't seem to be starting correctly.
Hint 1.1
Before diving deep, what's the high-level status of the problematic pod? Use kubectl to check if it's even scheduled or attempting to run.
Hint 1.2
For detailed troubleshooting information about a specific pod, including recent events and configuration details, which kubectl command provides the most comprehensive output?
You've found the problem with the pod-01 pod. Now, correct the pod's configuration so that it starts successfully.
Hint 2.1
How can you change the definition of a resource that already exists in Kubernetes? There's a kubectl command specifically for editing live objects.
Hint 2.2
Alternatively, you could delete the incorrect pod using kubectl delete and then create a new one with changes (either using kubectl run or kubectl apply with a corrected YAML file).
Now investigate the pod named pod-02. This one is also failing to run properly.
Hint 3.1
To figure out why the pod-02 pod's container fails, you need to investigate. Which kubectl commands let you see detailed pod status, historical events, and the output logs from the container itself?
Hint 3.2
Think about how Kubernetes objects are updated. Can you change every setting on a pod after it's created using commands like kubectl edit? Or are some core properties, perhaps like the main command a container runs, fixed at creation time?
Hint 3.3
When direct editing isn't possible or appropriate for the change needed, a common workflow is to replace the existing object. What kubectl operations would achieve removing the old pod and creating a new one with the corrected configuration? Remember to use the original busybox:latest image.
Finally, investigate the pod-03 pod. It seems to be stuck and won't start.
Hint 4.1
What does it usually mean when a pod remains in the Pending state for a long time? Use the primary kubectl command for detailed pod inspection to find out more about its current situation and history.
Hint 4.2
Investigate the pod's specification (spec). Are there any fields related to where the pod is supposed to run? Compare these requirements to the properties of the available nodes in your cluster. How can you view node details?
This concludes Part 1, focusing on basic startup and scheduling issues.