Kubernetes Deployments: Scaling, Updates & Rollbacks

Kubernetes Deployments: Scaling, Updates & Rollbacks
Welcome! This challenge explores Kubernetes Deployments, the standard way to manage stateless applications like web servers etc. Unlike individual Pods, Deployments provide declarative updates, scaling, and self-healing capabilities.
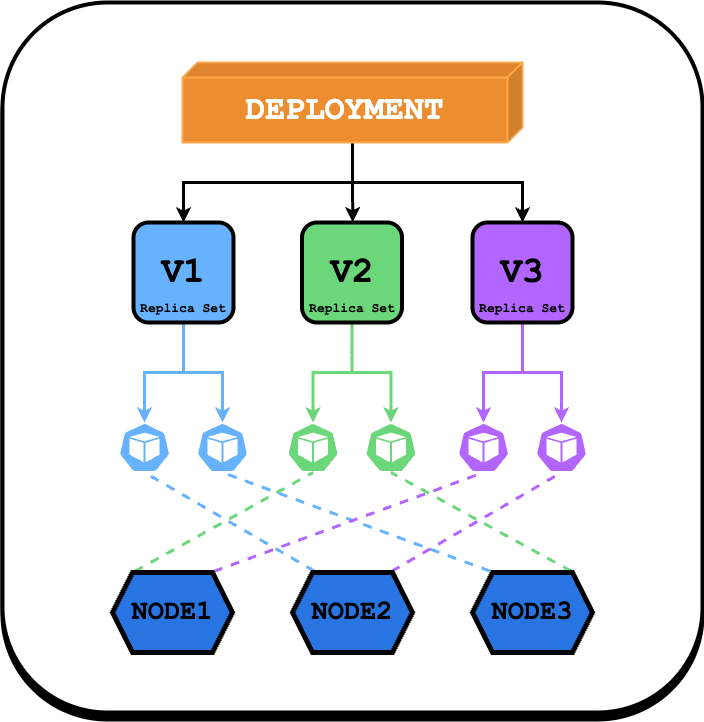
Before diving in, let's clarify the relationship between key components:
- Deployment: This is the high-level object you typically interact with. You define the desired state of your application here, including the container image, number of replicas, and update strategy.
- ReplicaSet: A Deployment doesn’t manage Pods directly. Instead, it creates and manages a ReplicaSet. The ReplicaSet’s job is to make sure the right number of identical Pods are always running. If one fails, it creates a new one to replace it.
- Pods: These are the actual instances of your application container(s), managed by a ReplicaSet, which is orchestrated by the Deployment.
Let's deploy the first version of our application.
Hint 1.1
There are kubectl commands to both imperatively create a deployment directly or declaratively apply a configuration file (YAML) defining the deployment.
Hint 1.2
A Deployment needs several key pieces of information: a name, the container image to run, and how many copies (replicas) are desired. How would you specify these details when creating the Deployment?
Hint 1.3
Once created, how can you confirm that the Deployment exists and has reached its desired state (i.e., the correct number of Pods are running and available)? Which kubectl commands help you observe resources and their status?
Now that the initial deployment is running, let's adjust the number of running instances to handle more load.
Hint 2.1
You need to change the desired number of replicas for the existing webapp Deployment. Is there a specific kubectl command designed for adjusting the scale of workload resources?
Hint 2.2
Besides using a dedicated command, think about the Deployment's definition itself. How could changing the configuration file or editing the live object achieve the goal of adjusting the replica count?
With the application scaled, it's time to deploy a new image version, webapp:v2. Let's see how Deployments handle this update.
Hint 3.1
How do Deployments typically handle changes to the application image version they manage? Consider what part of the Deployment definition specifies the container to run.
Hint 3.2
Consider the kubectl commands used for managing Deployments. Is there one specifically for changing the image used by a deployment? Alternatively, how could you modify the deployment's definition directly?
The update to webapp:v2 has been initiated. Now, observe the rollout process and check the status of the Pods.
Hint 4.1
It's useful to check the individual Pods managed by the deployment. How can you list these pods and observe their STATUS column? Look for statuses other than Running.
You've identified that the update to webapp:v2 is causing problems. The safest course of action is usually to revert to the last known good configuration.
Hint 5.1
Kubernetes Deployments keep track of previous versions (revisions). How can you view this history to understand what changes were made?
Hint 5.2
Once you know which revision represents the previous stable state, how do you instruct the Deployment controller to revert back to that specific configuration? Consider the kubectl verbs related to managing deployment updates and history.
Hint 5.3
After initiating the rollback, how can you monitor its progress and confirm that the deployment has successfully returned to the desired state with the correct image and replica count?
This concludes the challenge on Deployment fundamentals. You've practiced creating, scaling, updating, and rolling back stateless applications – essential skills for managing workloads in Kubernetes!