Terminate the Entire Process Group When One Process Runs Out of Memory
Premium Challenge
Upgrade your membership to unlock this and all other premium materials.
In a typical "master-worker" architecture, the primary process (the master) spawns multiple worker processes to handle tasks concurrently. This pattern is common in web servers (Nginx, Apache), database servers (PostgreSQL), and can also be found in proprietary applications.
An interesting problem to solve with such applications is how to control the memory usage of the entire group of processes. When a memory limit is set on a cgroup containing the primary process and its worker processes, the OOM killer may (and often will) send a SIGKILL signal to only one of the processes in the group - usually the one that is using the most memory at the time of the OOM event. If a worker process gets terminated, and the primary process doesn't handle it gracefully, it may lead to a hung application and/or inconsistent states (see Tracking Down “Invisible” OOM Kills in Kubernetes for a real-world example).
In this challenge, you will work with two specific processes: hogherder and memhog.
The hogherder process spawns several memhog subprocesses,
each of which consumes a large amount of memory.
Your task is to configure a cgroup such that if any memhog process exceeds the memory limit,
the OOM killer terminates the entire process group, including the primary hogherder process.
The assignment involves running the hogherder and its subprocesses in a cgroup
with a CPU limit of 20% and a total memory limit of 500 MB.
Good luck!
Hint 1
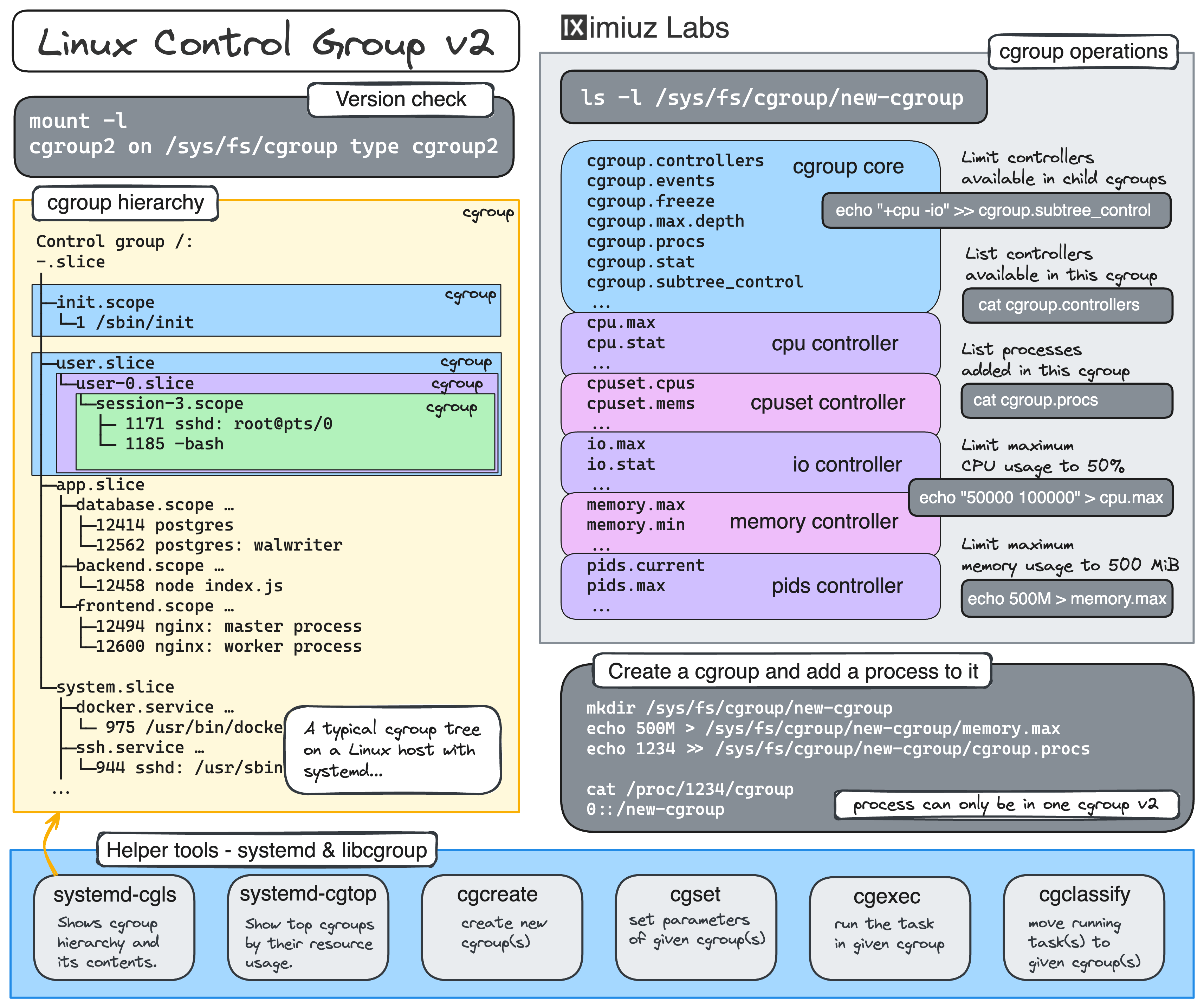
This challenge builds upon the Limit CPU and Memory Usage of a Linux Process challenge, so you may want to solve that first if you haven't already.
Hint 2
If you chose systemd-run to start the hogherder process,
you may need to additionally tweak the cgroup it creates.
While it's technically possible to achieve a close to the desired outcome with systemd-run -p OOMPolicy=kill ...,
in this challenge, your goal is to configure the OOM killer's behavior using native cgroup means only.
Hint 3
While cgroups are hierarchical creatures, and parent's cgroup settings are inherited by child cgroups,
due to the limitations of the solution checker, you'll need to configure the hogherder's own cgroup
(or the closest systemd slice if you decided to follow systemd-run --slice ... path).
Hint 4
Got the CPU and memory limits set correctly but some of the processes are still running even after the out-of-memory event?
Try writing 1 to the cgroup's memory.oom.group file 😉